|
Программные системы и вычислительные методы
Правильная ссылка на статью:
Золотухина Д.Ю. Сравнительный анализ индексационных стратегий в PostgreSQL при различных сценариях нагрузки // Программные системы и вычислительные методы. 2025. № 1. С. 21-31. DOI: 10.7256/2454-0714.2025.1.73138 EDN: UUZPDW URL: https://nbpublish.com/library_read_article.php?id=73138
Сравнительный анализ индексационных стратегий в PostgreSQL при различных сценариях нагрузки
Золотухина Дарья Юрьевна
независимый исследователь
394062, Россия, Воронежская область, г. Воронеж, пер. Антокольского, 4
Zolotukhina Daria
Independent researcher
394062, Russia, Voronezh region, Voronezh, lane Antokolsky, 4

|
dar.zolott@gmail.com
|
|
 |
Другие публикации этого автора
|
|
|
DOI: 10.7256/2454-0714.2025.1.73138
EDN: UUZPDW
Дата направления статьи в редакцию:
24-01-2025
Дата публикации:
03-04-2025
Аннотация:
Предметом исследования является эффективность различных индексационных стратегий, реализованных в PostgreSQL, и их влияние на производительность операций SELECT, UPDATE и INSERT в условиях различных масштабов данных. Объектом исследования выступают индексы B-Tree, GIN и BRIN, применяемые для оптимизации работы баз данных. Автор подробно рассматривает такие аспекты темы, как временные характеристики выполнения операций, размер индексов и их ресурсоемкость. Особое внимание уделяется влиянию объема данных на производительность индексов и их пригодности для работы с различными типами данных, включая JSONB. Исследование направлено на систематизацию знаний о применении индексов для повышения эффективности работы высоконагруженных систем, где требуется оптимизация операций доступа, обновления и вставки данных, а также анализ потребления ресурсов. Ведущим методом исследования является эмпирический подход, включающий разработку тестовой базы данных с таблицами orders, customers и products. Эксперименты проводились для операций SELECT, UPDATE и INSERT на малых, средних и больших объемах данных. Для анализа использовались метрики времени выполнения запросов и размера индексов, полученные с использованием инструментов PostgreSQL. Новизна исследования заключается в комплексном сравнении индексов B-Tree, GIN и BRIN в PostgreSQL с учетом не только временных характеристик выполнения запросов, но и их влияния на размер базы данных и общую нагрузку на систему. В отличие от существующих исследований, сосредоточенных на отдельных аспектах индексирования, данная работа рассматривает эффективность различных типов индексов в условиях изменяющейся нагрузки и различных категорий операций. Основными выводами проведённого исследования являются рекомендации по выбору индексов в зависимости от типов запросов и условий их выполнения. Индексы B-Tree подтвердили свою универсальность, демонстрируя высокую производительность для операций SELECT и UPDATE. GIN-индексы показали преимущества для работы с JSONB-данными, но их использование ограничено высокой ресурсоемкостью. BRIN-индексы доказали свою эффективность для больших объемов данных, особенно для операций SELECT. Особым вкладом автора в исследование темы является создание рекомендаций для разработчиков баз данных, что позволяет повышать производительность приложений за счёт оптимального выбора индексационной стратегии.
Ключевые слова:
индексационные стратегии, индексы B-Tree, индексы BRIN, индексы GIN, оптимизация запросов, производительность PostgreSQL, реляционные базы данных, JSONB-данные, высоконагруженные системы, управление данными
Abstract: The subject of the study is the effectiveness of various indexing strategies implemented in PostgreSQL and their impact on the performance of SELECT, UPDATE and INSERT operations in conditions of different data scales. The object of the study are the B-Tree, GIN and BRIN indexes used to optimize the operation of databases. The author examines in detail such aspects of the topic as the time characteristics of operations, the size of indexes and their resource intensity. Special attention is paid to the impact of data volume on the performance of indexes and their suitability for working with various types of data, including JSONB. The research is aimed at systematizing knowledge about the use of indexes to improve the efficiency of highly loaded systems, which require optimization of access operations, updating and inserting data, as well as analysis of resource consumption. The leading research method is an empirical approach, which includes the development of a test database with orders, customers, and products tables. Experiments were conducted for SELECT, UPDATE, and INSERT operations on small, medium, and large amounts of data. The metrics of query execution time and index size obtained using PostgreSQL tools were used for the analysis. The novelty of the research lies in conducting a comprehensive performance analysis of the B-Tree, GIN, and BRIN indexes in PostgreSQL when performing typical operations on various amounts of data. The main conclusions of the conducted research are recommendations on the choice of indexes depending on the types of queries and their execution conditions. B-Tree indexes have proven their versatility, demonstrating high performance for SELECT and UPDATE operations. GIN indexes have shown advantages for working with JSONB data, but their use is limited by high resource intensity. BRIN indexes have proven to be effective for large amounts of data, especially for SELECT operations, due to their compactness and low overhead. A special contribution of the author to the research of the topic is the creation of recommendations for database developers, which makes it possible to improve application performance by choosing an optimal indexing strategy.
Keywords: indexing strategies, B-Tree indexes, BRIN indexes, GIN indexes, query optimization, PostgreSQL performance, relational databases, JSONB data, high-load systems, data management
Введение
Современные реляционные базы данных, такие как PostgreSQL, предоставляют широкие возможности для оптимизации запросов благодаря разнообразным стратегиям индексирования. Эффективность индексов в значительной степени определяет производительность операций доступа, обновления и вставки данных, особенно в условиях высоких нагрузок и больших объемов информации [1]. Несмотря на значительный прогресс в области индексирования, вопрос выбора оптимального типа индекса для конкретных сценариев работы остается актуальным. Это особенно важно для приложений, где тип операций, структура данных и масштаб нагрузки существенно варьируются.
Индексы B-Tree, GIN и BRIN, реализованные в PostgreSQL, представляют собой универсальные инструменты для решения различных задач. B-Tree индексы обеспечивают стабильную производительность и подходят для широкого спектра операций [2]. GIN-индексы оптимизированы для сложных запросов с использованием JSONB-типов данных, что делает их востребованными в современных приложениях, работающих с неструктурированной информацией [3]. BRIN-индексы, благодаря своей компактности, оказываются эффективными в сценариях с большими объемами данных и низкой интенсивностью обновлений [4]. Однако различия в производительности этих индексов в зависимости от характера операций и масштабов данных требуют дополнительного исследования для выявления их оптимальных областей применения [5].
Объектом исследования являются индексационные стратегии, применяемые в PostgreSQL, с акцентом на три наиболее распространенных типа индексов: B-Tree, GIN и BRIN. Эти индексы широко используются в высоконагруженных системах и оказывают значительное влияние на производительность баз данных.
Предметом исследования выступает эффективность применения различных индексов в зависимости от типа выполняемых операций (SELECT, UPDATE, INSERT), объема данных и особенностей их хранения. В работе проводится детальный анализ времени выполнения запросов, размера индексов и их влияния на производительность системы в разных сценариях нагрузки.
Настоящее исследование проводится с целью определения наилучших индексационных стратегий для PostgreSQL в условиях изменяющейся нагрузки. Работа направлена на систематизацию данных о времени выполнения операций и размерах индексов. Эксперименты осуществлялись на базе данных, содержащей таблицы orders, customers и products, которые моделируют реальные сценарии высоконагруженных систем. Полученные результаты представляют собой основу для рекомендаций по выбору индексационной стратегии, что особенно важно для повышения производительности приложений, работающих в условиях больших данных и высоких нагрузок.
Научная новизна исследования заключается в комплексном сравнении индексов B-Tree, GIN и BRIN в PostgreSQL с учетом не только временных характеристик выполнения запросов, но и их влияния на размер базы данных и общую нагрузку на систему. В отличие от существующих исследований [6, 7, 8], сосредоточенных на отдельных аспектах индексирования, данная работа рассматривает эффективность различных типов индексов в условиях изменяющейся нагрузки и различных категорий операций. Такой подход позволяет выявить закономерности их применения и сформулировать практические рекомендации по выбору оптимальной индексационной стратегии. Дополнительно проведен анализ зависимости размера индексов от увеличения объема данных, что даёт возможность прогнозировать рост инфраструктурных затрат при использовании различных стратегий индексирования.
Материалы и методы
В данном исследовании, направленном на анализ производительности различных типов индексов в PostgreSQL, эксперименты проводились на базе данных PostgreSQL версии 15.2. Эта версия была выбрана благодаря её поддержке широкого спектра индексов, включая B-Tree, GIN и BRIN, что позволило получить полное представление об их эффективности в различных сценариях использования [9].
Для построения тестовой среды была разработана база данных, включающая три таблицы: orders, customers и products. Структура таблиц и их наполнение были тщательно спроектированы с целью имитации реальных сценариев работы высоконагруженных систем. Таблица orders представляет собой список заказов, содержащий такие поля, как идентификатор заказа, идентификатор клиента, идентификатор товара, дата заказа и цена. Таблица customers хранит данные о клиентах, включая идентификаторы, имена и JSONB-метаданные о клиентах, что позволило протестировать индексы, специфичные для работы с JSONB-типами данных [10]. Таблица products содержит информацию о продуктах, включая идентификатор, название и цену.
Таблицы заполнялись с использованием псевдослучайных данных для создания нагрузочных сценариев, максимально приближенных к условиям реальных систем. Например, даты заказов распределялись равномерно в пределах одного года, а цены продуктов варьировались в пределах от 1 до 1000 единиц. Для каждой таблицы были созданы три варианта наполнения: малый объем (50 тысяч строк), средний объем (500 тысяч строк) и большой объем (5 миллионов строк). Это позволило оценить производительность индексов при разных масштабах данных. Данные были сгенерированы таким образом, чтобы исключить влияние аномалий и обеспечить репрезентативность результатов.
Эксперименты включали выполнение трех типов операций: SELECT, UPDATE и INSERT. Запросы были разработаны для оценки производительности индексов в различных сценариях. Пример запроса SELECT для таблицы orders:
SELECT *
FROM orders
WHERE order_date > '2023-01-01';
Для таблицы customers использовался JSONB-запрос:
SELECT *
FROM customers
WHERE interests @> '{"sports": true}';
Пример запроса UPDATE для таблицы products:
UPDATE products
SET price = price * 1.1
WHERE price BETWEEN 100 AND 500;
Пример запроса INSERT для таблицы orders:
INSERT INTO orders (customer_id, product_id, order_date, price)
SELECT generate_series(1, 100000),
random() * 1000,
NOW() - interval '1 day' * random() * 365,
random() * 1000;
В рамках исследования были протестированы индексы следующих типов:
- B-Tree — универсальный индекс, применимый для большинства запросов [11].
- GIN — предназначен для работы с JSONB-типами данных в таблице customers [12].
- BRIN — эффективен для работы с большими объемами данных в таблицах orders и products [13].
Замеры производительности проводились для каждой комбинации индекса, объема данных и типа операции. Основные метрики включали:
- Время выполнения — фиксировалось с использованием команды EXPLAIN ANALYZE и выражалось в миллисекундах (ms).
- Размер индекса — измерялся с помощью функций PostgreSQL (pg_relation_size) и выражался в мегабайтах (MB).
Эксперименты проводились на машине со следующими характеристиками:
- Процессор: Apple M2 @ 3.49 GHz, 8 ядер, 8 потоков.
- Оперативная память: 8 ГБ.
- Накопитель: 256GB PCIe® NVMe™ M.2 SSD.
Для каждого эксперимента создавалась одинаковая тестовая среда, исключающая влияние внешних факторов. Все замеры проводились многократно для получения точных и воспроизводимых результатов.
Полученные данные представлены в графической форме, что позволило проанализировать влияние объема данных, типа индекса и характера операции на производительность PostgreSQL.
Результаты
В ходе исследования были проанализированы временные показатели выполнения операций SELECT, UPDATE и INSERT на различных объемах данных (малый, средний, большой) с использованием индексов B-Tree, GIN, BRIN, а также в отсутствии индексов. Полученные данные представлены в графической форме, что позволяет наглядно оценить зависимость времени выполнения операций от объема данных и типа индекса.
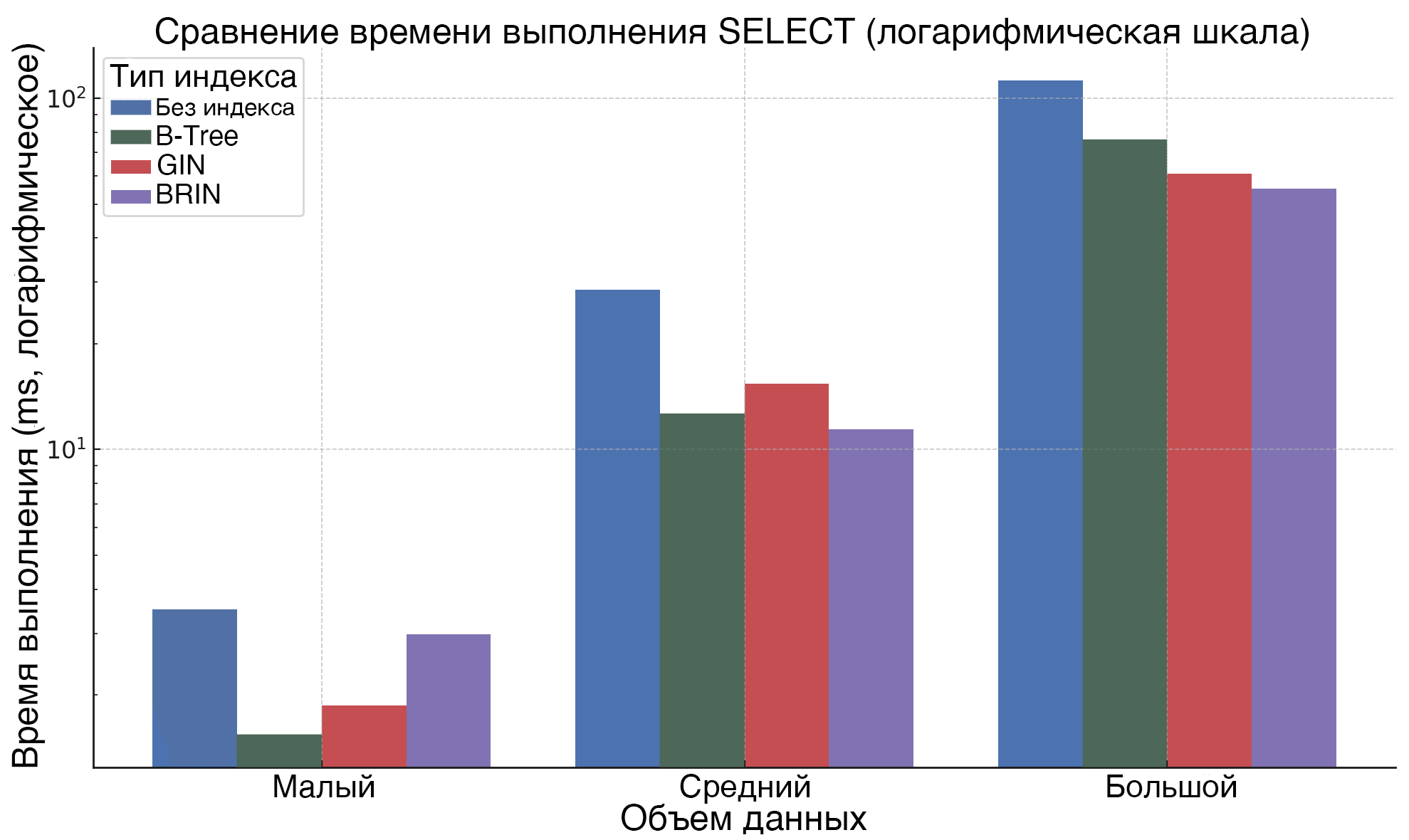
Рисунок 1. Влияние типа индекса и объема данных на время выполнения операции SELECT
На рисунке 1, отображающем результаты выполнения операции SELECT, видно, что при малом объеме данных использование индексов B-Tree, GIN и BRIN обеспечивает схожие временные характеристики, значительно превосходя выполнение без индекса. С увеличением объема данных эффективность GIN и B-Tree возрастает, однако индекс BRIN демонстрирует минимальное время выполнения для большого объема данных.
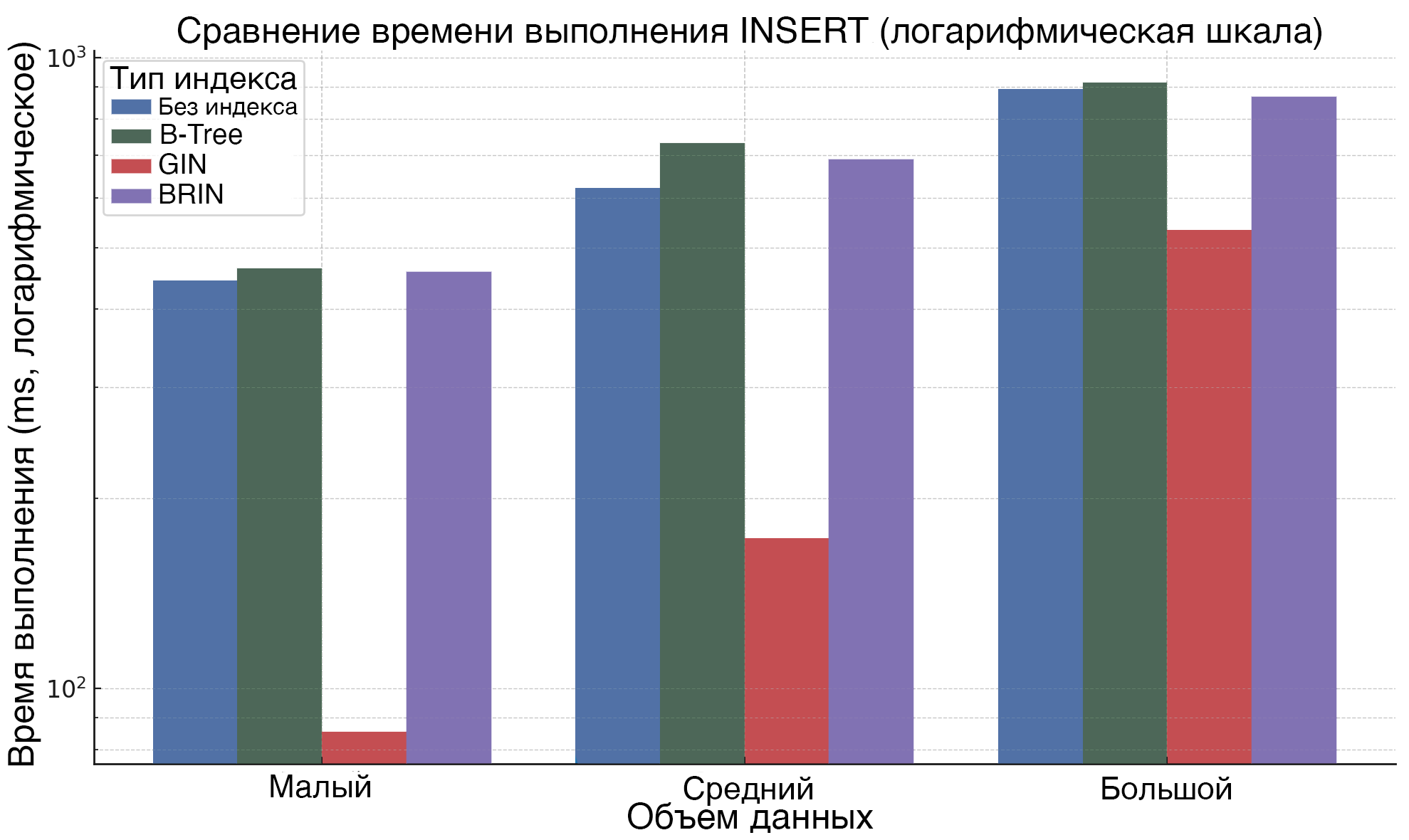
Рисунок 2. Влияние типа индекса и объема данных на время выполнения операции INSERT
Анализ операции UPDATE, который представлен на рисунке 2, показал, что при всех объемах данных наибольшую эффективность демонстрирует индекс B-Tree. GIN, напротив, увеличивает время выполнения операции на среднем и большом объемах данных. BRIN остается оптимальным выбором для большого объема данных, однако его преимущества становятся заметными только при значительных размерах таблиц.
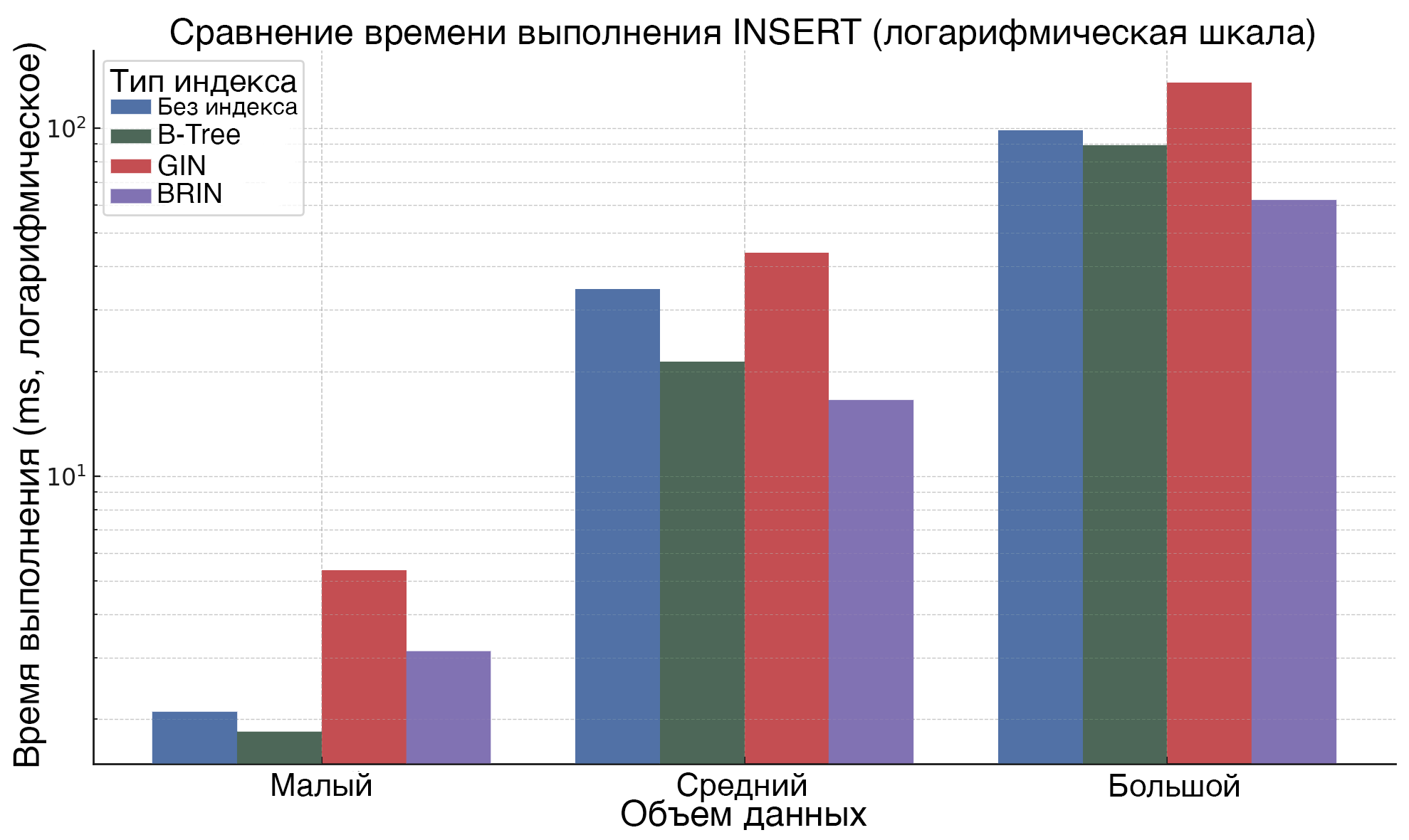
Рисунок 3. Влияние типа индекса и объема данных на время выполнения операции UPDATE
На рисунке 3 для операции INSERT видно, что индексы GIN и BRIN приводят к увеличению времени выполнения по сравнению с отсутствием индекса, особенно при большом объеме данных. Индекс B-Tree также несколько увеличивает время вставки, однако его влияние оказывается менее значительным.
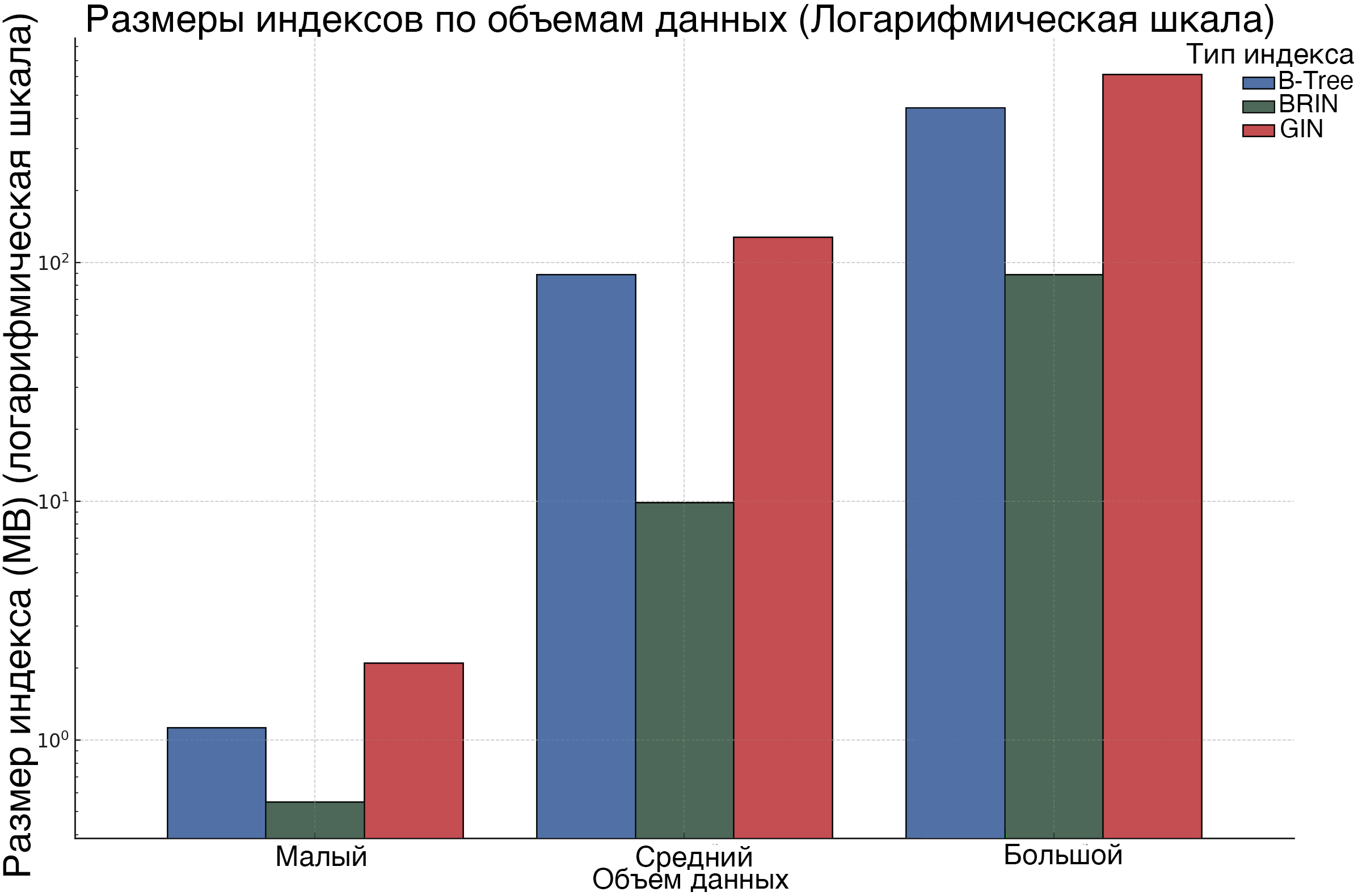
Рисунок 4. Размеры индексов различных типов в зависимости от объема данных
Размеры индексов зависят от их типа и объема данных, что отображено на рисунке 4. GIN-индексы демонстрируют наибольший размер, достигая 612.7 MB при большом объеме данных, тогда как B-Tree индексы занимают до 450.3 MB. BRIN-индексы остаются наиболее компактными, увеличиваясь до 92.1 MB при аналогичных условиях. Динамика изменения размеров индексов по мере роста объема данных показывает линейный рост для всех типов индексов, с наиболее заметным увеличением у GIN-индексов, что отражает их высокую ресурсоемкость при увеличении объема данных. B-Tree индексы растут более умеренно, сохраняя баланс между эффективностью и размером, а BRIN-индексы демонстрируют минимальные изменения, подчеркивая их экономичность в условиях больших объемов данных.
Обсуждение
Результаты экспериментов позволяют выявить характерные особенности каждого типа индекса в зависимости от объема данных и типа операции. Индексы B-Tree проявляют себя как универсальный выбор, демонстрируя стабильную производительность на всех объемах данных и для всех типов операций. Их эффективность при выполнении операций SELECT и UPDATE особенно заметна на больших объемах данных, где они сохраняют приемлемые временные характеристики без значительного увеличения времени выполнения.
Индексы GIN, несмотря на их превосходство в операциях SELECT с высокоиндексируемыми полями, оказываются менее подходящими для операций UPDATE и INSERT. Их ресурсоемкость и сложность обновления приводят к увеличению времени выполнения на средних и больших объемах данных. Эти особенности делают GIN-индексы релевантными в задачах, где частота обновления данных минимальна, а скорость выборки из сложных структур данных критична.
BRIN-индексы подтвердили свою эффективность для работы с большими объемами данных, особенно в операциях SELECT. Их компактная структура и минимальные накладные расходы на хранение делают их оптимальным выбором для анализа данных на уровне больших массивов. Однако их применение в операциях UPDATE и INSERT ограничено, так как их архитектура рассчитана на минимизацию издержек в сценариях, где обновление данных происходит реже, чем выборка.
Особое внимание заслуживают изменения в размерах индексов по мере роста объемов данных. Линейный рост, наблюдаемый у всех типов индексов, отражает их предсказуемость и масштабируемость. GIN-индексы показывают наиболее значительное увеличение размера, что указывает на необходимость тщательного учета их использования в системах с ограниченными ресурсами. B-Tree индексы демонстрируют более умеренное увеличение размера, что делает их сбалансированным выбором для систем, где необходимо сочетать производительность и экономичность. BRIN-индексы остаются наиболее компактными, что подтверждает их пригодность для обработки больших объемов данных с минимальными затратами памяти.
Заключение
Результаты проведённого исследования демонстрируют значительное влияние индексационных стратегий на производительность PostgreSQL в условиях различных сценариев нагрузки и масштабов данных. Эксперименты показали, что выбор типа индекса является критически важным решением, напрямую влияющим на эффективность операций SELECT, UPDATE и INSERT, особенно при увеличении объема данных.
Индексы B-Tree подтвердили свою универсальность и стабильность производительности, что делает их оптимальным выбором для большинства сценариев. Эти индексы показали минимальное время выполнения операций SELECT и UPDATE на больших объемах данных, а также приемлемые характеристики для операций INSERT, что подтверждает их сбалансированность между эффективностью и ресурсопотреблением.
GIN-индексы проявили себя как эффективный инструмент для сложных выборок JSONB-данных, однако их ресурсоемкость и длительное время выполнения операций UPDATE и INSERT ограничивают их применение в сценариях с высокой частотой изменений данных. Эти особенности делают GIN-индексы подходящими для аналитических систем, где преобладают операции чтения сложных структурированных данных.
BRIN-индексы показали свои преимущества в работе с большими объемами данных, особенно для операций SELECT, благодаря компактности и минимальным накладным расходам на хранение. Однако их применение в операциях INSERT и UPDATE требует осторожного подхода, учитывая специфику их архитектуры, ориентированной на редкое обновление данных.
Анализ изменений размеров индексов по мере роста объема данных подтвердил их линейный характер, что свидетельствует о предсказуемости и масштабируемости всех типов индексов. Наиболее значительное увеличение размера было зафиксировано для GIN-индексов, что подчёркивает необходимость их взвешенного использования в системах с ограниченными ресурсами.
Результаты исследования предоставляют разработчикам и администраторам баз данных практические рекомендации по выбору индексационной стратегии в PostgreSQL. Эти рекомендации могут быть полезны для построения высокоэффективных систем, где требуется баланс между производительностью, ресурсопотреблением и спецификой приложения.
Перспективы дальнейшего исследования включают расширение анализа на другие типы индексов, такие как Hash-индексы и GiST, с целью оценки их применимости в различных сценариях нагрузки. Дополнительным направлением может стать исследование влияния многоверсионности (MVCC) в PostgreSQL на производительность индексов при высокой степени конкурентного доступа. Важной задачей также является разработка адаптивных стратегий индексирования, позволяющих динамически изменять структуру индексов в зависимости от нагрузки и типов запросов.
Библиография
1. Домбровская Г. Оптимизация запросов в PostgreSQL. М.: ДМК-Пресс, 2022.
2. Mostafa A. S. A Case Study on B-Tree Database Indexing Technique // Journal of Soft Computing and Data Mining. 2020. № 27-3. URL: https://penerbit.uthm.edu.my/ojs/index.php/jscdm/article/view/6828 (дата обращения: 10.01.2025).
3. Borodin A., Mirvoda S., Porshnev S., Ponomareva O. Improving generalized inverted index lock wait times // Journal of Physics: Conf. 2018. №944. URL: https://iopscience.iop.org/article/10.1088/1742-6596/944/1/012022/pdf (дата обращения: 10.01.2025).
4. Borodin A., Mirvoda S., Kulikov I., Porshnev S. Optimization of Memory Operations in Generalized Search Trees of PostgreSQL // Communications in Computer and Information Science. 2017. № 716. URL: https://link.springer.com/chapter/10.1007/978-3-319-58274-0_19 (дата обращения: 10.01.2025).
5. Рогов Е. В. PostgreSQL 16 изнутри. М.: ДМК Пресс, 2024.
6. Морозов С. В., Нестеров С. А. Сравнительный анализ типов индексов в СУБД SQL Server и PostgreSQL // SAEC. 2024. № 2. С. 485–491.
7. Селиванов Е. О. Сравнение типов индексов в различных системах управления базами данных // Молодежь и наука: актуальные проблемы фундаментальных и прикладных исследований: Материалы VI Всероссийской национальной научной конференции молодых учёных. Комсомольск-на-Амуре: Комсомольский-на-Амуре государственный университет, 2023. С. 357–361.
8. Кудашов А. С., Агапова В. А., Дьячков Д. А., Казакова И. А. Обзор типов индексов и их применение в системах управления базами данных // Современные цифровые технологии. Материалы II Всероссийской научно-практической конференции. Барнаул: Алтайский государственный технический университет им. И. И. Ползунова, 2023. C. 299–303.
9. Documentation PostgreSQL 15 – URL: https://www.postgresql.org/docs/15/release-15-2.html (date of access: 10.01.2025).
10. Сорокин В. Е. Хранение и эффективная обработка нечетких данных в СУБД PostgreSQL // Программные продукты и системы. 2017. № 4. URL: https://app.amanote.com/v4.1.10/research/note-taking?resourceId=Pprz23MBKQvf0Bhi37cu (дата обращения: 10.01.2025).
11. B-tree индексы в базах данных на примере PostgreSQL. – URL: https://techtrain.ru/talks/e2273ec8ca2b4ea692c65318a50c4be5 (дата обращения: 10.01.2025).
12. Меджидов Р. Г. Анализ многоколоночных индексов баз данных // Актуальные проблемы прикладной математики, информатики и механики : Сборник трудов Международной научной конференции. Воронеж : Научно-исследовательские публикации, 2019. C. 420–422.
13. Богатов И. В. Эффективная оптимизация запросов в СУБД Postgres / Академическая публицистика. 2022. № 5-2. C. 59–64.
References
1. Dombrovskaya, G. (2022). Query optimization in PostgreSQL. Moscow: DMK-Press.
2. Mostafa, A. S. (2020). A Case Study on B-Tree Database Indexing Technique. Journal of Soft Computing and Data Mining, 27-3. https://penerbit.uthm.edu.my/ojs/index.php/jscdm/article/view/6828
3. Borodin, A., Mirvoda, S., Porshnev, S., & Ponomareva, O. (2018). Improving generalized inverted index lock wait times. Journal of Physics: Conf, 944. https://iopscience.iop.org/article/10.1088/1742-6596/944/1/012022/pdf
4. Borodin, A., Mirvoda, S., Kulikov, I., & Porshnev, S. (2017). Optimization of Memory Operations in Generalized Search Trees of PostgreSQL. Communications in Computer and Information Science, 716. Retrieved from https://link.springer.com/chapter/10.1007/978-3-319-58274-0_19
5. Rogov, E. V. (2024). PostgreSQL 16 from the inside. Moscow: DMK Press.
6. Morozov, S. V., Nesterov, S. A. (2024). Comparative analysis of index types in SQL Server and PostgreSQL DBMS. SAEC, 2, 485–491.
7. Selivanov, E. O. (2023). Comparison of index types in various database management systems. Youth and Science: Current Issues of Fundamental and Applied Research: Proceedings of the VI All-Russian National Scientific Conference of Young Scientists. Komsomolsk-on-Amur: Komsomolsk-on-Amur State University. Pp. 357–361.
8. Kudashov, A. S., Agapova, V. A., Dyachkov, D. A., Kazakova, I. A. (2023). Review of index types and their application in database management systems. Modern Digital Technologies. Proceedings of the II All-Russian Scientific and Practical Conference. Barnaul: Polzunov Altai State Technical University. Pp. 299–303.
9. Documentation PostgreSQL 15. https://www.postgresql.org/docs/15/release-15-2.html
10. Sorokin, V. E. (2017). Storage and efficient processing of fuzzy data in PostgreSQL. Software Products and Systems, 4. https://app.amanote.com/v4.1.10/research/note-taking?resourceId=Pprz23MBKQvf0Bhi37cu
11. B-Tree Indexes in Databases: The Example of PostgreSQL. https://techtrain.ru/talks/e2273ec8ca2b4ea692c65318a50c4be5
12. Medzhidov, R. G. (2019). Analysis of multicolumn database indexes. Current problems of applied mathematics, computer science, and mechanics: Proceedings of the International Scientific Conference. Voronezh : Nauchno-issledovatelskie publikatsii. Pp. 420–422.
13. Bogatov, I. V. (2022). Efficient optimization of queries in PostgreSQL. Academic journalism. Ufa: Aeterna. Pp. 59–64.
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Предмет исследования рецензируемой работы – эффективность применения различных индексов в российской версии бесплатной системы управления базами данных с открытым исходным кодом PostgreSQL при различных сценариях нагрузки в зависимости от типа выполняемых операций (SELECT, UPDATE, INSERT), объема данных и особенностей их хранения.
Методология исследования базируется на проведении экспериментов и сравнительном анализе времени выполнения запросов, размера индексов и их влияния на производительность системы в условиях изменяющейся нагрузки и различных категорий операций с применением графических методов представления полученных результатов.
Актуальность исследования авторы связывают с тем, что современные реляционные базы данных предоставляют широкие возможности для оптимизации запросов благодаря разнообразным стратегиям индексирования, которые влияют на производительность операций доступа, обновления и вставки данных, особенно в условиях высоких нагрузок и больших объемов информации, а также с недостаточной научной проработкой вопроса выбора оптимального типа индекса для конкретных сценариев работы.
Научная новизна рецензируемого исследования заключается в комплексном сравнении индексов B-Tree, GIN и BRIN в PostgreSQL с учетом не только временных характеристик выполнения запросов, но и их влияния на размер базы данных и общую нагрузку на систему.
В тексте статьи выделены следующие разделы: Введение, Материалы и методы, Результаты, Обсуждение, Заключение и Библиография.
В работе рассматривается некоммерческая версия объектно-реляционной системы управления базами данных, основанной на программе POSTGRES, разработанной на факультете компьютерных наук Калифорнийского университета в Беркли. В публикации акцент сделан на сравнительном анализе трех наиболее распространенных типов индексов, широко используемых в высоконагруженных системах и оказывающих значительное влияние на производительность баз данных: B-Tree, GIN и BRIN. В статье отражено влияние типа индекса и объема данных на время выполнения операций SELECT, INSERT, UPDATE; показаны размеры индексов различных типов в зависимости от объема данных. Продемонстрировано значительное влияние индексационных стратегий на производительность PostgreSQL в условиях различных сценариев нагрузки и масштабов данных. Эксперименты показали, что выбор типа индекса является критически важным решением, напрямую влияющим на эффективность вышеназванных операций особенно при увеличении объема данных.
Библиографический список включает 13 источников – современные научные публикации отечественных авторов на русском и английском языках, а также интернет-ресурсы по рассматриваемой теме, на которые в тексте приведены адресные ссылки, что подтверждает наличие апелляции к оппонентам.
Рецензируемый материал соответствует направлению журнала «Программные системы и вычислительные методы», отражает результаты проведенной авторами работы, может вызвать интерес у читателей, рекомендуется к опубликованию.
|







