|
DOI: 10.7256/2454-0714.2022.1.37341
Дата направления статьи в редакцию:
18-01-2022
Дата публикации:
08-02-2022
Аннотация:
Предметом исследования являются методы построения архитектур агрегаторов информации, методы повышения масштабируемости и производительности подобных систем, методы уменьшения задержки между публикациями нового контента источником и появления его копии в агрегаторе информации. В данном исследовании под агрегатором контента будет подразумеваться распределенная высоконагруженная информационная система, собирающая информацию из различных источников в автоматическом режиме, обрабатывающая и отображающая ее в обработанном виде на специальном веб-сайте или мобильном приложении. Особое внимание уделяется рассмотрению принципов работы агрегаторов контента, таких как: основные стадии агрегации и критерии выборки данных, автоматизация процессов агрегации, технология обработки данных и объем их копирования. Автор подробно рассматривает основные научно-технические проблемы агрегации контента, такие как веб-кроулинг, обнаружение нечетких дубликатов, суммаризация, выработка политики обновления агрегированных данных. Основным результатом данного исследования является разработка высокоуровневой архитектуры системы агрегации контента. В исследовании также даются основные рекомендации по выбору архитектурных стилей и специального программного обеспечения, позволяющего построить подобную систему, такого как системы управления распределенными базами данных и брокеры сообщений. Дополнительным вкладом автора в исследование темы является подробное описание архитектур некоторых составляющих компонентов исследуемой системы агрегации контента, таких как веб-кроулер и система определения нечетких дубликатов. Основным выводом исследования является то, что к построению систем агрегации контента необходимо подходить с точки зрения принципов построения распределенных систем. В подобных системах могут быть выделены три логических части разделения ответственности: часть, отвечающая за агрегацию контента, часть, производящая обработку данных, т.е., парсинг, группировку, классификацию, суммаризацию и т.д., а также часть, отвечающая за представление агрегированной информации.
Ключевые слова:
Агрегация контента, Архитектура распределенной системы, Веб-краулинг, Определение нечетких дубликатов, Стадии агрегации контента, Критерии выборки данных, Суммаризация, Высоконагруженная система, Пуассоновский процесс, Микросервисная архитектура
Abstract: The subject of this research is the key methods for creating the architecture of information aggregators, methods for increasing scalability and effectiveness of such systems, methods for reducing the delay between the publication of new content by the source and emergence of its copy in the information aggregator. In this research, the content aggregator implies the distributed high-load information system that automatically collects information from various sources, process and displays it on a special website or mobile application. Particular attention is given to the basic principles of content aggregation: key stages of aggregation and criteria for data sampling, automation of aggregation processes, content copy strategies, and content aggregation approaches. The author's contribution consists in providing detailed description of web crawling and fuzzy duplicate detection systems. The main research result lies in the development of high-level architecture of the content aggregation system. Recommendations are given on the selection of the architecture of styles and special software regime that allows creating the systems for managing distributed databases and message brokers. The presented architecture aims to provide high availability, scalability for high query volumes, and big data performance. To increase the performance of the proposed system, various caching methods, load balancers, and message queues should be actively used. For storage of the content aggregation system, replication and partitioning must be used to improve availability, latency, and scalability. In terms of architectural styles, microservice architecture, event-driven architecture, and service-based architecture are the most preferred architectural approaches for such system.
Keywords: Content aggregation, Distributed system architecture, Web crawling, Fuzzy duplicates detection, Content aggregation stages, Data sampling criteria, Summarization, High load system, Poisson process, Microservices architecture
Introduction
The amount of data on the Internet is growing rapidly and there is an obvious need for special systems that help collect and organize it. This problem is successfully solved with a help of content aggregators.
In this study, a content aggregator is considered as a distributed high-load information system that automatically collects information from various sources, processes and displays it on a website or mobile application or provides some API to access the gathered data.
The purpose of this study is to propose an architecture for a content aggregation system, based on the research conducted on web crawling technologies, summarization, searching for fuzzy duplicates, methods of increasing, methods to reduce the delay between the publication of new content by the source and the appearance of its copy in the information aggregator, methods to increase the scalability and performance of similar systems.
When building content aggregation systems, it is necessary to solve many problems both inherent in the subject area and common for systems that process a large amount of information and have high traffic or performance requirements.
This study explores the main issues and approaches to creating content aggregators. The relevance of the research topic is explained by the widespread use of content aggregation systems in information technologies. The research results can be used to build content aggregation systems or for other similar high-load distributed systems.
This paper is structured as follows. Section 1 explains the relevance of content aggregators. Section 2 discusses the basic principles of content aggregators. Section 3 covers the main aggregation stages. Section 4 overviews some of the main scientific and technological problems of content aggregation. Section 5 provides an overview of the related works. Section 6 presents the high-level architecture of the proposed content aggregation system. Finally, Section 7 provides a conclusion and some directions for future work.
1 Relevance of content aggregators
As of August 2021, there are more than 1 billion 211 million sites in the world, of which about 201 million are active [1]. The total number of pages exceeds 50 billion [2]. Such a huge amount of data makes the Internet more and more important for users, whose number is constantly increasing, currently numbering more than 5 billion 168 million people [3].
Thanks to Web 2.0 technologies, the growing mobile web audience, and the ever-expanding possibilities of media services, users are creating more and more data [4]. IDC predicts that the Global Datasphere will grow to 175 Zettabytes by 2025 [5, p. 3] and we can see that digital transformation has already affected all areas of our lives, and many companies do business exclusively on the Internet, opening new markets and improving their business processes to gain a competitive advantage.
Having gained access to a huge amount of information, users have faced the problem of finding relevant data. Moreover, users often find it difficult to choose which website can provide data in the most valuable and efficient way [6].
These problems are solved by content aggregators that collect and distribute information from various sources and display it in a user-friendly format and design. Content aggregators combine information from different sources in one place, providing users with a unified interface, responsive design, full-text search, various additional features in the form of sending special notifications or saving a publication for further reading, as well as high-speed access to content. Due to the tremendous data volume processed, unlike many newspaper publishers and news agencies.
Content aggregators are not limited to news gathering since there are numerous services that aggregate job ads (Indeed.com, Jooble.com), real estate ads, RSS feeds (Feedly.com), social media (Taggbox.com), blogs (Flipboard.com), reviews, etc. It means that content aggregation technology is widely used to collect various information and many successful companies have been built around this business model.
2 The basic principles of content aggregators
2.1 A simplified model of a content aggregation system
In a simplified representation, a content aggregation system consists of a data aggregation component and a component for aggregated data presentation. This model is shown in Figure 1.
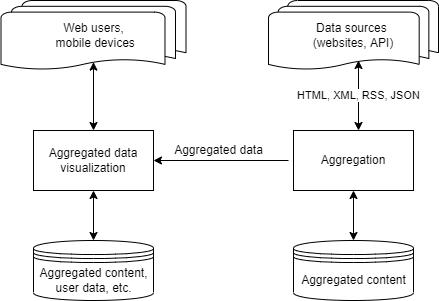
Figure 1 – A simplified model of a content aggregation system
Figure 1 illustrates a content aggregation process: an Aggregation server uses a job scheduler to send requests to the data sources (websites, third-party APIs), the data is then processed and saved to the content aggregator’s database. The next step is to transfer the data from the content aggregator’s database to the Aggregated data visualization server. The visualization server hosts a website or application that handles user requests and displays structured data.
2.2 Main criteria for data sampling
Since the main purpose of the system based on content aggregation technology is to provide a relevant response to a query [7], the main criteria for data sampling are considered [7, 8]:
1. Citation rate: The number of references to this document in other documents, excluding references in affiliated media and self-citation.
2. Freshness (uniqueness): Time of publication of the document compared to other sources.
3. Informativeness: A number of keywords per document.
4. No spam or irrelevant content: Data containing unwanted advertisements or illegal content should not be displayed to the end-user.
Thus, the sources that meet the above characteristics will be shown to users at the top of others. This means that content aggregation systems must contain a data ranking engine powerful enough to handle a huge number of publications.
2.3 Automation of aggregation processes
There are several approaches to content aggregation:
1. Automatic mode: Almost all well-known content aggregators, use web crawlers that aggregate data from multiple sources.
2. Automatic mode with manual moderation: Some content aggregators have a team of editors and moderators that can add posts manually and control the aggregated publications (Anews, Yahoo, Rambler) [9].
3. Manual mode: Very few large companies provide content aggregation services that work by manually adding information. In many cases, information systems of this kind are high-traffic sites that have evolved from systems based on automatic content aggregation. For example, Yandex Realty moved to work with its advertisement base, since the business model of automatic data aggregation made it difficult to monetize the project [10].
2.4 Content copy strategies
One of the most used approaches of content gathering is when the full copy of the publication is created. For example, social media aggregator Flipboard operates this way.
The second method is also often used, which is partial copying, in which some necessary part is aggregated: for example, only headers or a header with a short description. An example of such aggregation would be Mediametrics which aggregates news headlines or Anews which aggregates the first paragraph of a news headline [9].
It is also possible to combine both copying strategies discussed above, which is logical, especially when working with different data sources and different types of aggregated materials.
2.5 Content aggregation approaches
There are several commonly used content aggregation approaches, which are: RSS-based aggregation, web page scraping, API-based aggregation. All these approaches are often used when aggregating content and have some advantages and disadvantages.
RSS [11] is a well-known web feed standard, an XML-formatted plain text. According to research [12] by Yahoo!, most of the information disseminated through RSS feeds is news, blogs, media podcasts, and product data. This means that through RSS feeds, websites strive to deliver the latest information to their users. This aggregation strategy works well for news aggregators, job aggregators, or blog aggregators.
Web scraping [13, 14] is an automated process of extracting data from websites using special programs that usually parse a document object model (DOM) and extract the necessary information. For example, if the RSS channel does not contain the full text for publications, it is possible to get by fetching the corresponding publication pages and parsing their HTML markup.
Using an API-based approach, content aggregators provide an API interface that allows the owner of the data source to connect and deliver data in a specific format. Almost all large companies use XML and JSON formats to transfer data. For example, Yandex has developed a special format named YML [15] (Yandex Market Language), based on XML, to simplify the loading of price lists. Yandex also has another standard for blog and news aggregation, allowing clients to upload data using REST API or XML-based format. Jooble.com also has similar functionality for job ads aggregation [16].
This approach is very attractive to publishers, as in this way they increase the size of their audience. For example, publishers that cooperate with Yandex News effectively broadcast their content by sending 40 thousand messages per day to the service, and in return receiving 4 million hits to their sites from readers of the news aggregator. Readers will find out the news on the service (15 million unique visitors per day), ranked according to the established rules, and processed by a robot [7].
3 Content aggregation stages
A simplified model of the content aggregation system has been presented in Section 2.1. This section describes one of its parts – the aggregation mechanism in terms of the stages of aggregation. Typically, the content aggregation process includes four main stages [17], which are shown in Figure 2.
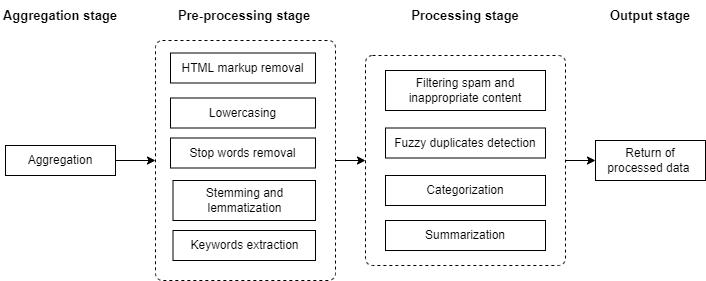
Figure 2 – The content aggregation stages
As Figure 2 shows, the content aggregation process begins with an Aggregation stage, which involves crawling data sources (articles, reviews, job postings, etc.) across the web. At this stage, high-performance web crawler agents are required to deal with huge amounts of data.
Pre-processing stage is one of the most important, at which the necessary information is extracted from the received data and then the special processing of this data is carried out. It often includes HTML markup removal, lowercasing, stop words removal, stemming [18] and lemmatization [19], keywords extraction [20, 21].
At the Processing stage, aggregated data is grouped (by meaning, relevance, source, etc.), and then such activities as spam and inappropriate content filtering [22], fuzzy duplicates detection [23], categorization (classification according to the subject of the content) [24, 25], and summarization [26] are performed. Finally, at the Output stage, the processed data is returned.
It was shown above that at each stage of aggregation, many scientific and technical problems arise. Some of them will be discussed in Section 4.
4 The scientific and technical problems of content aggregation
4.1 Web crawling
The web scraping process that was mentioned previously can’t do without web crawling. Web crawlers are the essential components of content aggregation and are widely used by content aggregators and search engines. Typically, crawlers fetch web pages based on some initial set of URLs and expand the URL database using parsed URLs from the aggregated web pages. The problem of building a web crawler is compounded by the sheer volumes of data: effective web crawlers must download and, depending on the task, revisit hundreds of millions of web pages.
Many researchers have studied web crawler technology over the past several decades, including its design, crawling strategies, scalability, fault tolerance, storage, and indexing techniques.
For example, paper [27] describes a design and implementation of a high-performance distributed web crawler, whose preliminary results for 5 million hosts are 120-million-page loads.
Paper [28] outlines the design of the WebFountain crawler that is implemented for IBM. WebFountain can crawl the entire web repeatedly, keeping a local repository database containing some metadata for each web page.
Paper [29] describes UbiCrawler, a platform-independent and linearly scalable Java-written crawler system that can download more than 10 million pages per day using five downloading nodes.
A scalable and extensible web crawler Mercator which has been used in many data mining projects, including Alta Vista, is described in [30]. The paper contains its design and details on performance.
The main functions of RCrawler, presented in paper [31], are multithreading scanning, content extraction, and duplicate content detection. In addition, it includes features such as URL and content type filtering, depth control, and a robot.txt parser. RCrawler has a highly optimized system and can load many pages per second while being resistant to certain crashes and spider traps.
CAIMANS [32] is a search robot that works with unstructured resources from the Internet using semantic technologies and K-means clustering [33]. Relevant data are selected based on cosine similarity and NLP techniques [34].
Finally, there is a comprehensive survey of the science and practice of web crawling [35] which focuses on crawler architecture, crawl ordering problems, and other challenges related to this area of research.
The studies mentioned above put particular emphasis on the high performance and scalability of the web crawler architecture. In general, a well-designed web crawler should meet the following requirements [27, 30]:
1. Flexibility: The system should support modifications and new components integration.
2. High performance and scalability: The performance of a powerful web crawler usually starts at a few hundred pages per second and the system should be easily scalable to such a configuration.
3. Reliability and fault tolerance: Web crawlers should deal with wrong HTML markup, different server responses, encodings. Also, the system must be able to stay alive after one (or more) of its nodes is out of order.
4. Configurability: The crawling system’s behavior should consider the robots.txt files and do not send too many requests to the website. At least, it should be possible to set up the request per website frequency and URL pattern to avoid parsing unnecessary pages.
The architecture of an incremental web crawling system based on [27, 30, 32, 35] is shown in Figure 3.
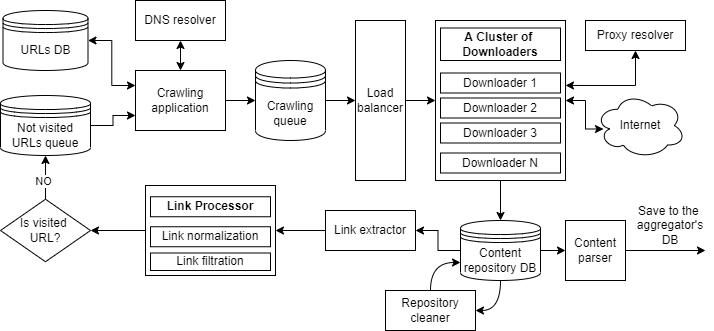
Figure 3 – A web crawling system architecture
As shown in Figure 3, the crawler’s design is divided into several main parts to meet the requirements described above: a Crawling application, a Crawling queue, a Load balancer, a Cluster of downloaders, and other components in charge of processing the crawled content, such as a Link extractor, a Repository cleaner, a Content parser, and a Link processor.
The Crawling application uses data from two sources: a URLs database (which stores visited links) and a Not visited URLs queue. It takes the URLs to crawl from those sources and resolves their IP addresses using a DNS resolver component. Next, it forms a message containing hundreds of URLs and sends it to the Crawling queue. Finally, the URLs from the Not visited URLs queue are saved to the URLs database.
After receiving the messages from the crawling application, the Crawling queue resends them to the Load balancer. The Crawling queue is considered a potential bottleneck and a single point of failure. It means that the distributed message queue systems such as RabbitMQ [36] or Apache Kafka [37] should be used there to achieve good load balancing, high performance, and low latency.
The Load balancer component is used to distribute the requests to the downloaders. According to this approach, the requests will be sent only to the online servers. This layer can be built using NGINX [38, 39] or HAProxy [40], there are also a lot of cloud solutions like Amazon ELB [41] or Cloud Load Balancing [42].
The cluster of downloaders consists of at least several servers with downloader applications that fetch the web pages from the Internet and save it to the content repository database. Downloader is not responsible for the parsing process, it saves the web page as is, or gets the content of thetag. Crawling is performed by multiple worker threads, typically numbering in the hundreds [30].
The Link extractor parses all links from the aggregated web pages and passes them to the Link processor which normalizes and filters the links according to the aggregation rules: for example, it can only leave links that follow some predefined pattern. After that, new links are added to the queue for not visited links for further crawling.
The Content parser component is responsible for parsing content stored in the repository database and transferring it to the content aggregator’s database. The Repository cleaner cleans up the processed data from the repository database and leaves only some metadata.
4.2 Fuzzy duplicate detection
Detecting fuzzy duplicates is a difficult task, very common for systems dealing with a tremendous amount of data, especially for content aggregators. It could be explained as a problem of finding data records that relate to the same entity, which is quite common in large aggregating systems since there are multiple representations of the same object. These duplicates are very hard to identify because of the large volume of aggregated data and this can affect data quality and performance.
A successful solution to this problem leads to the removal of redundant information and its grouping by content. Performance improvements are achieved in a variety of ways, including by hashing meaningful words or sampling a set of substrings of text [23].
One of the well-known approaches for fuzzy duplicate detection was introduced by Udi Manber [43]. This method uses checksums (fingerprints) created for substrings of the same length.
In addition, the method proposed by Andrei Broder [44] is actively used, based on the representation of a document in the form of a set of sequences of fixed length, consisting of consecutive words (shingles). According to the method, if the cardinality of the intersection of the sets of shingles of two documents is large enough, then such documents can be considered similar. Further development of the shingle method was proposed in the study [45].
There are also a lot of duplicate record identification methods based on the semantic-syntactic information of similarity [46]: blocking methods that are based on grouping of a set of records into separated partitions and comparing all pairs of records only within individual blocks; windowing methods that sort the data by key and navigate the sorted data using a sliding window, comparing only the entries in it; semantic methods which approach is based on relationships between the analyzed data and its meaning.
A workflow of a fuzzy duplicate detection system based on the sorted neighborhood method (SNM) [47] is demonstrated in Figure 4.
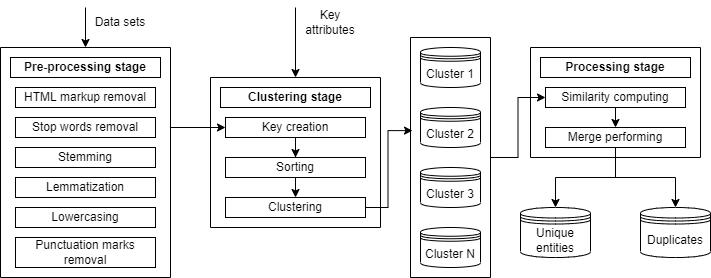
Figure 4 – A fuzzy duplicates detection system based on the SNM method
The system demonstrated in Figure 4 processes records from combined datasets. At a Pre-processing stage data is cleared of HTML tags, lowercasing, stemming, and stop words removal tasks are performed before starting a Clustering stage.
At the Clustering, keys are computed for each record by extracting key attributes. Next, those records are sorted using the keys and clustered by the SNM algorithm to gather the records that are most likely to be duplicated in one cluster.
At the Processing stage, the similarity is computed, and some records are sent to the database with unique records, while others are stored as duplicates.
4.3 Summarization
One of the most actual problems at the processing stage of content aggregation is automatic text summarization. It is not a new area of research and has been actively studied since the second half of the 20th century [26].
Summarization can be defined as the automatic creation of a summary (title, summary, annotation) of the original text. There are two different summarization methods: extractive [48] and abstractive [49].
Extractive summaries are produced by extracting the most significant paragraphs, sentences, or keywords from the source text. The final text summary is created using a text ranking algorithm that can use, for example, the term frequency or a position of the extracted unit.
On the other hand, the abstractive method is the automatic creation of new text based on the input documents. It is hard to design abstractive systems due to their heavy reliance on linguistic techniques [26]. A systematic literature review on abstractive text summarization is shown in the paper [50].
Summarization is very resource-intensive and depends on the data and algorithms used to process the text. To perform summarization, different approaches can be used. For example, paper [51] proposes a high-level architecture for an extractive summarization system for processing documents in different languages using machine learning technologies. A system for COVID-19 information retrieval which uses an abstractive summarization approach is shown in the paper [52].
Summarization algorithms to create automatic summaries for Twitter posts were compared in the paper [53]. According to the results, the simple frequency-based summarization algorithms – Hybrid TF-IDF (based on TF-IDF algorithm [54]) and SumBasic [55] produced the best results both in F-measure scores and in human evaluation scores and can be successfully used in the summarization of aggregated content.
In some cases, when aggregating data via RSS or when parsing pages with news lists, summarization may be skipped because the processed data already contain the summaries and perhaps some keywords or taxonomy tags.
4.4 Retrieval policy and change detection of aggregated data
Change detection of aggregated data is an urgent scientific and technical problem. According to [56], to minimize the expected total obsolescence time of any page, the access to that page should be as evenly spaced in time as possible. But data sources are updated independently, and computational resources are limited. This means that a specific change detection strategy is required to detect and download as many changed web pages as possible.
The retrieval policy problem is associated with finding ways to reduce the delay between the publication of new content by the source and the appearance of its copy in the database of a content aggregator. This issue is also explained by the complexity of updating the search index as the aggregated data increases.
If aggregated pages change randomly and independently, at a fixed rate over time, a Poisson process is often used to detect such changes. For example, in paper [57] a formal framework is presented that provides a theoretical foundation for improving the freshness of aggregated data using a homogeneous Poisson process. According to the research, a homogeneous Poisson model is appropriate for change events with a frequency of at least one month.
Paper [58] argues that a homogeneous Poisson model becomes unacceptable for retrieval policy when time granularity is shorter than one month. For example, a well-designed RSS aggregator can’t wait a month to get the latest articles. It is proposed to use the inhomogeneous Poisson model, where the posting rate changes over time.
Many studies try to find an update policy that maximizes the time-averaged relevance of the aggregator database and meets the bandwidth constraints. The study [59] uses a Maximum Likelihood Estimator (MLE) approach based on assessing the rate of change of web pages, determining the parameter value that maximizes the probability of observing a page change.
Moment Matching (MM) estimator [60], uses an approach that is based on analyzing the proportion of cases when no changes were found during page access, and then, using the moment matching method, the frequency of changes is estimated. The Naive estimator [61, 62] simply uses the average number of detected changes to roughly estimate the rate of page change.
The Naive estimator approach, MM, and MLE estimators are discussed in [64]. These estimators have been shown to suffer from instability and computational intractability. This fact means that every estimator approach must be rigorously tested against real data to identify all the pros and cons before making the final decision on use.
Investigation of the optimal synchronization frequency and verification of the applicability of the Poisson process for its determination is complicated by the need to use many resources for collecting and storing information. For example, in paper [57] a database of 42 million pages collected from 270 major sites over four months was used. The results of the study [58] were obtained based on processing 10,000 RSS feeds. The first version of the Google search engine [64] can give us an idea of the size of the aggregated data, which then exceeded 147 GB, and now can be obviously much more.
5 Related works
Content aggregation systems can differ in data aggregation and processing methods, architecture, purpose, performance, etc. This section provides a brief overview of some of them.
5.1 SocConnect, a personalized social media aggregator
SocConnect [65] is a social media content aggregator and recommendation system. It collects data from popular social networks and allows to combine and group friends, tag friends, and social activities, and provides the personal recommendations of activities to individual users based on the prediction generated using their ratings on previous social data. SocConnect also uses machine learning to improve the performance of personalized recommendations.
To obtain social data, SocConnect uses the authentication methods provided by social networks, including their APIs to download information about friends and their activities. For heterogeneous social data representation across the social networks, a unified schema was used based on FOAF [66] and activity stream [67].
5.2 Atlas, a news aggregator
Atlas [47] is a web application that aggregates news from the RSS and APIs of various news sources, as well as Twitter posts. The application offers features that are specific to the existing news aggregators, such as selecting sources, grouping them according to various criteria, bringing information into a common, easy-to-read format, or saving articles for later reading. Atlas also filters ads and removes spam.
From the architectural point of view, Atlas consists of a Web server module, a Content download module, a Storage of articles, and a Web interface module.
The Web server module is organized as a REST service [69] written in Python [70] using the Flask [71] framework and is used for processing the HTTP requests from customers.
The Content download module extracts articles from RSS feeds, news APIs, and Twitter, taking advantage of multiprocessing and multithreading to improve performance. Incoming tasks from the Web server module are added to the Redis [72] queue for further processing. The Web server does not wait for their completion, thereby achieving asynchrony.
The article storage module uses MySql [73] and Redis in such a way that the aggregated articles are stored in JSON format, and the primary key to access the article collection from the source is the link to the RSS feed. The web interface module is built using AngularJS [74] and serves as an access point to the Atlas API.
5.3 NewsBird, a matrix-based news aggregator
NewsBird is a news aggregator using Matrix News Analysis (MNA). MNA groups numerous articles into cells of a user-generated matrix and then summarizes the topics of the article in each cell. This approach provides flexible analysis of different categories of news and allows users to control the analysis process using their knowledge of the subject area.
The NewsBird architecture includes a Data gathering and article extraction module, an Analysis module, a Visualization module, and a database that stores aggregated articles.
Since the NewsBird works with news in different languages, the aggregated news is translated into English using a machine translation service, which makes it possible to efficiently summarize the aggregated information and model topics. Then the data are parsed and added to the Apache Lucene [76] index. The pre-processing, i.e., tokenization, lowercasing, stop words removal, and stemming is performed by Lucene [77].
NewsBird uses Latent Dirichlet allocation [78] for topic extraction and TF-IDF for summarization. The Visualization module provides users with the functionality of accessing the news by obtaining their overview, which is organized as a list of topics, sorted by importance. Users can also read summaries of related articles.
5.4 PNS, a personalized news aggregator
Personalized News Service (PNS) is a news aggregator [49] which provides its users with personalized access to the news gathered from various sources. Personalization is done based on the individual user interaction, user similarities, and statistical analysis performed using machine learning. The architecture of the PNS consists of a Content scanning module, a Content database, a Content selection module, and a Content presentation module.
The Content scanning module is responsible for content aggregation, which is performed on a schedule based on the list of sources and associated URL addresses that are stored in a database. Information is aggregated from RSS feeds and HTML pages and there are two corresponding parsers for this. Aggregated content is parsed using regular expressions, and this approach assumes a writing parser for each of the content sources and is considered hard to maintain because the HTML markup can change very frequently and unpredictably.
The Content selection module is based on a separate general-purpose personalization server called PServer [80] which runs like a web service using the HTTP protocol and returning XML data. This module provides personalized views based on personal interests (personal news), similar characteristics (stereotyped news), communities, and related news.
The Content presentation module is a graphical user interface of the PNS and is responsible for identifying the user, providing personalized content, informing the PServer of user actions, and providing a search function.
5.5 Google prototype
Paper [64] gives a high-level overview of how one of the first versions of Google worked. The system’s design can be divided into several main parts: crawling, indexing, and ranking using the PageRank algorithm [81] which was used for searching through the aggregated data.
The web crawling was performed by several distributed crawlers written in the Python programming language and supporting about 300 simultaneous connections. At peak loads, the system was able to crawl over 100 pages per second using 4 crawlers. To improve performance, each crawler supported a DNS cache.
The aggregated data was saved in a repository, then indexed and transformed into a set of occurrences of words (hits), which were later used to create a partially sorted forward index.
The study also emphasizes that data structures should be optimized for large collections of documents to perform crawling, indexing, and searching at a low cost. The system was designed to avoid disk seeks whenever possible, and almost all the data was stored in big files which are virtual tiles that can create multiple tile systems and support compression.
6 Proposed system
6.1 High-level architecture of content aggregation system
This section explains a high-level architecture of a content aggregation system based on the basic operating principles and underlying technologies commonly used in such systems as described above.
Since in this study a content aggregation system is considered as a distributed system, that is, a collection of autonomous computing elements (nodes) that appears to its users as a single coherent system [82, 83], it must support such distributed systems’ design principles like openness (i.e., it should be easy to add new resource sharing services and make them available for use by other services), scalability (i.e., it should remain effective when there is a significant increase in the number of resources and the number of users), failure handling and fault tolerance, transparency, security, and concurrency [84, pp. 17-25].
These principles can be met by using the most appropriate architectural styles as well as tools and technologies that allow to handle the heavy workloads and to deal with big data effectively. In this case, the most preferred architectural styles for such a system are microservices architecture, event-driven architecture, and service-based architecture [85, pp. 119-265] because they improve, for example, scalability, fault tolerance, and openness.
As shown above, there are many scientific and technical challenges in creating content aggregators such as summarization, fuzzy duplicate detection, scheduling, parsing, web crawling, stemming, lemmatization, clustering, etc., which require large computation power for their processing. To increase its performance, various caching methods, load balancers, and message queues should be actively used. For the storage of a content aggregation system, replication and partitioning must be used to improve availability, latency, and scalability [86, pp. 151-217].
It is supposed that these technologies and architectural styles are used in the construction of the proposed system, but they are not covered in this study to avoid unnecessary complications and detail.
The proposed high-level architecture of a content aggregation system is shown in Figure 5.
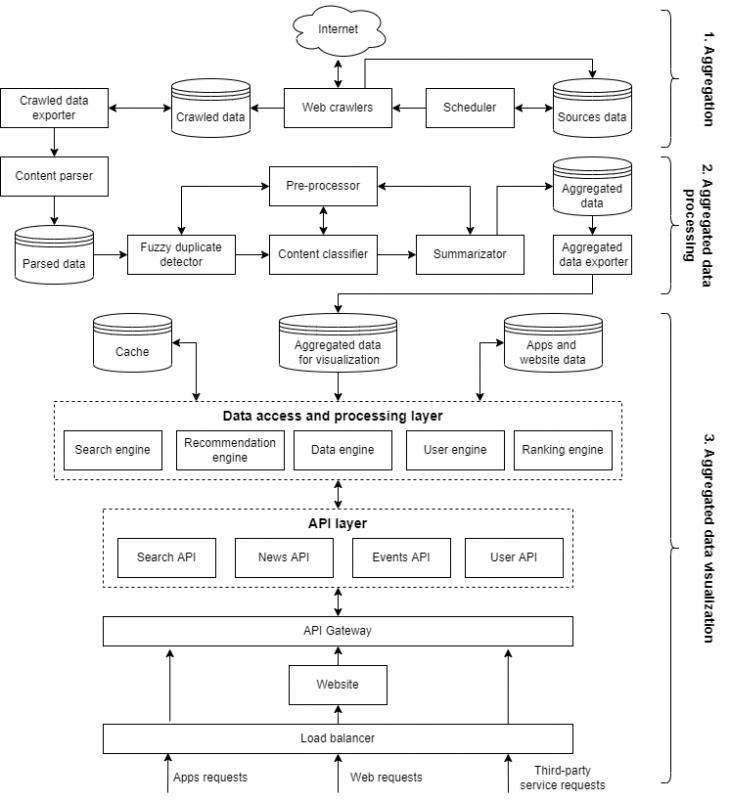
Figure 5 – A high-level architecture of a content aggregation system
The architecture shown in Figure 5 can be logically divided into several parts: an Aggregation part, an Aggregated data processing part, and a Visualization part, which in turn consists of a web interface (a component named Website represents a website or a group of websites), an API layer, and a Data access layer. These parts are described in the following, focusing on the most important architectural components.
6.2 The aggregation part
The main components of the aggregation part of the proposed content aggregation system are a Scheduler, a set of Web crawlers, and a Crawled data exporter.
The Scheduler component is responsible for the retrieval and change detection policies developed based on the Sources data and can use, for example, the Poisson process (see Section 4.4). It calls the distributed set of Web crawlers (see Section 4.1) to get the data from the Internet sources according to the aggregation rules. The aggregated information is then saved to the Crawled data storage. Web crawlers do not participate in the parsing process, the crawled data save as is, with minimal manipulations to reduce the time of crawling.
The Crawled data exporter analyses the Crawled data database and exports aggregated information for further processing. It runs on schedule and cleans up the aggregated data, leaving only the necessary metadata in the Crawled data storage to reduce its size. The main content copy strategies and aggregation approaches that can be used in this step are described in Section 2.4 and Section 2.5.
6.3 The aggregated data processing part
The main components of the aggregated data processing part are a Content parser, a Pre-processor, a Fuzzy duplicate detector, a Content classifier, a Summarizator, and an Aggregated data exporter. At this stage, the aggregated content should be parsed, filtered, and grouped according to the business needs and saved to the database for further exporting to the visualization part of the system.
The Crawled data exporter passes aggregated data to the Content parser component that performs data parsing and saves the processed information to the Parsed data database.
Then data is automatically retrieved from the Parsed data database with a help of a special scheduler associated with this task and goes to the Fuzzy duplicates detector to identify the fuzzy duplicates (see Section 4.2).
The next step is content classification using the Content classifier component. This component is responsible for spam and inappropriate content detection and categorizes data into groups and subgroups according to content value and attributes. This module can be organized as a hybrid categorical expert system that combines an approach based on the use of knowledge base and rules with the implementation of neural networks as described in the paper [87].
The Summarizator component automatically creates summaries for the content and then data is stored in the Aggregated data database. As it follows from Figure 5, the Summarizator like the Fuzzy duplicate detector and the content classifier uses the Pre-processor module to perform HTML markup removal, lowercasing, stop words removal, stemming, and lemmatization, keywords extraction as described in Section 3.
Finally, the Aggregated data exporter brings out data to the visualization part of the content aggregation system. At this step, the exported data are the business entities containing the necessary metadata and information about the related entities, represented in the convenient format and ready for further displaying to the end-user.
6.4 Aggregated data visualization part
The aggregated data visualization part of the proposed system should handle the client requests and display the data in an appropriate format. One of the key components of this part of the system is a Load balancer, which distributes requests from the applications (for example, mobile apps), web users, and third-party services (these can be, for example, another content aggregators) to a Web site and API components.
The Website component is a web interface that allows users to access the aggregated content. This component can provide different functionality depending on the business requirements, including searching through the aggregated data, reading the pages with aggregated information, grouping data based on the user profile, user management, and administrational functionality.
Requests from the Load balancer component are finally translated into requests to the API layer, which come through the API Gateway module [88, 89, 90]. This approach allows dynamic routing, security, and traffic monitoring, forwarding requests to the API layer for further processing.
The APIs send requests to the Data access and processing layer, which contains special applications to perform a search, data ranking, recommendations, user management, statistics, etc. Some of these applications can be implemented using out-of-box solutions, for example, the searching functionality can be built using Apache Lucene [91, 92] or Elastic Search, read requests can be handled by Apache Cassandra [93], and Hadoop [94, 95] can be used to analyze logs and statistics.
Another important component of the Data processing layer is the Cache module that is used to decrease the load and allows faster access to the services. Each of the Data processing modules can have its caching mechanism.
7. Conclusion and future work
This article deals with the problem of creating content aggregators. In particular, the basic principles of the content aggregators have been considered, including the content aggregation stages, the scientific and technical problems of content aggregation, such as web crawling, fuzzy duplicate detection, summarization, retrieval policy, and change detection.
Based on the research conducted during this study, the architecture of the content aggregation system has been proposed, which includes the main described principles and technologies. The proposed design aims to provide high availability, scalability for high query volumes, and big data performance.
Using this research as a basis, the author’s next step can be a development of a prototype of such a content aggregation system along with finding a better way for parsing web pages semantically.
Библиография
1. August 2021 Web Server Survey // Netcraft News [Website]. 2021. URL: https://news.netcraft.com/archives/2021/08/25/august-2021-web-server-survey.html (last accessed: 18.01.2022).
2. Maurice de Kunder. The size of the World Wide Web (The Internet) // WorldWideWebSize.com. Daily Estimated Size of The World Wide Web [Website]. 2021. URL: https://www.worldwidewebsize.com (last accessed: 18.01.2022).
3. World Internet Users and 2021 Population Stats // Internet World Stats [Website]. 2021. URL: https://www.internetworldstats.com/stats.htm (last accessed: 18.01.2022).
4. G. Paliouras, A. Mouzakidis, C. Skourlas, M. Virvou, C. L. Jain. PNS: A Personalized News Aggregator on the Web // Intelligent Interactive Systems in Knowledge-Based Environments. 2008. URL: https://doi.org/10.1007/978-3-540-77471-6_10 (last accessed: 18.01.2022).
5. David Reinsel, John Gantz, John Rydning. The Digitization of the World – From Edge to Core // An IDC White Paper. 2018. 28p. URL: https://www.seagate.com/files/www-content/our-story/trends/files/idc-seagate-dataage-whitepaper.pdf (last accessed: 18.01.2022).
6. S. Chowdhury, M. Landoni. News aggregator services: user expectations and experience // Online Information Review. 2006. URL: https://doi.org/10.1108/14684520610659157 (last accessed: 18.01.2022).
7. Храмова Н. Н. Спецификация генерации новостей через RSS на примере работы агрегатора Яндекс. Новости // Знак: проблемное поле медиаобразования. 2015. №3 (17). URL: https://cyberleninka.ru/article/n/spetsifikatsiya-generatsii-novostey-cherez-rss-na-primere-raboty-agregatora-yandeks-novosti (last accessed: 18.01.2022).
8. Шагдарова Б. Б. Новостные агрегаторы в интернете // Вестник БГУ. Язык, литература, культура. 2017. №1. URL: https://cyberleninka.ru/article/n/novostnye-agregatory-v-internete (last accessed: 18.01.2022).
9. Масенков В. В. Агрегация контента в России и в мире: есть ли будущее у новостной агрегации? [Электронный ресурс] // Медиа-коммуникационный форум RIW 15, 21–23 октября 2015, Россия, Москва, Экспоцентр. URL: http://files.runet-id.com/2015/riw/presentations/22oct.riw15-green-1--masenkov.pdf (last accessed: 18.01.2022).
10. Иван Бушухин. "Яндекс" изменил политику работы с объявлениями о недвижимости. [Website] // РБК Недвижимость. 2014. URL: https://realty.rbc.ru/news/577d23ca9a7947a78ce91950 (last accessed: 18.01.2022).
11. RSS 2.0 Specification. [Website] // RSS Advisory Board. URL: https://www.rssboard.org/rss-specification (last accessed: 18.01.2022).
12. Joshua Grossnickle, Todd Board, Brian Pickens, Mike Bellmont. RSS–Crossing into the Mainstream. // Yahoo! 2005. – 12 p. URL: https://content.marketingsherpa.com/heap/cs/rsscharts/7.pdf (last accessed: 18.01.2022).
13. K. Sundaramoorthy, R. Durga, S. Nagadarshini. NewsOne — An Aggregation System for News Using Web Scraping Method // International Conference on Technical Advancements in Computers and Communications (ICTACC). 2017. URL: http://dx.doi.org/10.1109/ICTACC.2017.43 (last accessed: 18.01.2022).
14. Moskalenko A. A., Laponina O. R., Sukhomlin V. A. Developing a Web Scraping Application with Bypass Blocking // Modern Information Technology and IT-education. 2019. №2. URL: https://doi.org/10.25559/SITITO.15.201902.413-420 (last accessed: 18.01.2022).
15. YML and CSV formats [Website]. // Yandex Support. URL: https://yandex.com/support/partnermarket/export/yml.html#yml-format (last accessed: 18.01.2022).
16. Job aggregator in the USA, post jobs on Jooble [Website]. URL: https://jooble.org/partner/ppc (last accessed: 18.01.2022).
17. Alaa Mohamed, Marwan Ibrahim, Mayar Yasser, Mohamed Ayman, Menna Gamil, Walaa Hassan. News Aggregator and Efficient Summarization System. // International Journal of Advanced Computer Science and Applications (IJACSA). 2020. URL: http://dx.doi.org/10.14569/IJACSA.2020.0110677 (last accessed: 18.01.2022).
18. A. Jabbar, S. Iqbal, M. I. Tamimy. Empirical evaluation and study of text stemming algorithms // Artificial Intelligence Review. 2020. URL: https://doi.org/10.1007/s10462-020-09828-3 (last accessed: 18.01.2022).
19. T. Bergmanis, S. Goldwater. Context sensitive neural lemmatization with Lematus // Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. URL: http://dx.doi.org/10.18653/v1/N18-1126 (last accessed: 18.01.2022).
20. G. Salton, C. Buckley. Term-weighting approaches in automatic text retrieval // Information Processing & Management. 1988. URL: https://doi.org/10.1016/0306-4573(88)90021-0 (last accessed: 18.01.2022).
21. Y. Zhang, Y. Zhou, J. T. Yao. Feature Extraction with TF-IDF and Game-Theoretic Shadowed Sets // Information Processing and Management of Uncertainty in Knowledge-Based Systems. IPMU 2020. Communications in Computer and Information Science. 2020. URL: https://doi.org/10.1007/978-3-030-50146-4_53 (last accessed: 18.01.2022).
22. Yuliya Kontsewaya, Evgeniy Antonov, Alexey Artamonov. Evaluating the Effectiveness of Machine Learning Methods for Spam Detection // Procedia Computer Science. 2021. URL: https://doi.org/10.1016/j.procs.2021.06.056 (last accessed: 18.01.2022).
23. Зеленков Ю. Г., Сегалович И. В. Сравнительный анализ методов определения нечетких дубликатов для Web-документов // Труды 9-ой Всероссийской научной конференции «Электронные библиотеки: перспективные методы и технологии, электронные коллекции» RCDL’2007: Сб. работ участников конкурса.-Т. 1.-Переславль-Залесский: «Университет города Переславля», 2007.-С. 166–174. URL: http://elib.ict.nsc.ru/jspui/bitstream/ICT/1233/1/segal_65_v1.pdf (last accessed: 18.01.2022).
24. Daniel López-Sánchez, Angélica González Arrieta, Juan M. Corchado. Visual content-based web page categorization with deep transfer learning and metric learning // Neurocomputing. 2019. URL: https://doi.org/10.1016/j.neucom.2018.08.086 (last accessed: 18.01.2022).
25. Adrita Barua, Omar Sharif, Mohammed Moshiul Hoque. Multi-class Sports News Categorization using Machine Learning Techniques: Resource Creation and Evaluation // Procedia Computer Science. 2021. URL: https://doi.org/10.1016/j.procs.2021.11.002 (last accessed: 18.01.2022).
26. Abdelkrime Aries, Djamel eddine Zegour, Walid Khaled Hidouci. Automatic text summarization: What has been done and what has to be done. // ArXiv. 2019. URL: https://arxiv.org/pdf/1904.00688.pdf (last accessed: 18.01.2022).
27. V. Shkapenyuk, T. Suel. Design and implementation of a high-performance distributed Web crawler //Proceedings of the 18th International Conference on Data Engineering. San Jose, CA, USA. 2002. URL: https://doi.org/10.1109/ICDE.2002.994750 (last accessed: 18.01.2022).
28. J. Edwards, K. S. McCurley, J. A. Tomlin. An adaptive model for optimizing performance of an incremental web crawler // Proceedings of the 10th International World Wide Web Conference. 2001. URL: http://dx.doi.org/10.1145/371920.371960 (last accessed: 18.01.2022).
29. P. Boldi, B. Codenotti, M. Santini, and S. Vigna. UbiCrawler: A scalable fully distributed web crawler // Software — Practice & Experience. 2004. № 8, pp. 711–726. URL: https://doi.org/10.1002/spe.587 (last accessed: 18.01.2022).
30. Allan Heydon, Marc Najork. Mercator: A scalable, extensible Web crawler // World Wide Web 2. Palo Alto, CA, USA. 1999. №4. URL: https://doi.org/10.1023/A:1019213109274 (last accessed: 18.01.2022).
31. Salim Khalil, Mohamed Fakir. RCrawler: An R package for parallel web crawling and scraping // SoftwareX. 2017. URL: https://doi.org/10.1016/j.softx.2017.04.004 (last accessed: 18.01.2022).
32. Ida Bifulco, Stefano Cirillo, Christian Esposito, Roberta Guadagni, Giuseppe Polese. An intelligent system for focused crawling from Big Data sources // Expert Systems with Applications. 2021. URL: https://doi.org/10.1016/j.eswa.2021.115560 (last accessed: 18.01.2022).
33. Hyunjoong Kim, Han Kyul Kim, Sungzoon Cho. Improving spherical k-means for document clustering: Fast initialization, sparse centroid projection, and efficient cluster labeling // Expert Systems with Applications. 2020. URL: https://doi.org/10.1016/j.eswa.2020.113288 (last accessed: 18.01.2022).
34. Bifulco, I., Cirillo, S. Discovery multiple data structures in big data through global optimization and clustering methods // Proceedings of the 22nd international conference information visualisation. 2018. URL: http://dx.doi.org/10.1109/iV.2018.00030 (last accessed: 18.01.2022).
35. Christopher Olston, Marc Najork. Web Crawling // Foundations and Trends. 2010. №3. URL: http://dx.doi.org/10.1561/1500000017 (last accessed: 18.01.2022).
36. M. Rostanski, K. Grochla, A. Seman. Evaluation of highly available and fault-tolerant middleware clustered architectures using RabbitMQ // Proc. Of Federated Conference on Computer Science and Information Systems. 2014. URL: http://dx.doi.org/10.15439/978-83-60810-58-3 (last accessed: 18.01.2022).
37. Nguyen C. N., Hwang S., Jik-Soo Kim. Making a case for the on-demand multiple distributed message queue system in a Hadoop cluster // Cluster Computing. 2017. №20. URL: https://doi.org/10.1007/s10586-017-1031-0 (last accessed: 18.01.2022).
38. High-Performance Load Balancing [Website] URL: https://www.nginx.com/products/nginx/load-balancing/ (last accessed: 18.01.2022).
39. Бобров А. В., Рубашенков А. М. Настройка прокси-сервера Nginx // Academy. 2019. №5 (44). URL: https://cyberleninka.ru/article/n/nastroyka-proksi-servera-nginx (last accessed: 18.01.2022).
40. HAProxy Technologies. The World’s Fastest and Most Widely Used Software Load Balancer [Website]. URL: https://www.haproxy.com/ (last accessed: 18.01.2022).
41. Elastic Load Balancing [Website]. URL: https://aws.amazon.com/elasticloadbalancing/ (last accessed: 18.01.2022).
42. Cloud Load Balancing. High-performance, scalable load balancing on Google Cloud Platform [Website]. URL: https://cloud.google.com/load-balancing/ (last accessed: 18.01.2022).
43. U. Manber. Finding Similar Files in a Large File System // Proc. USENIX WINTER Technical Conference. 1994. URL: https://www.cs.arizona.edu/sites/default/files/TR93-33.pdf (last accessed: 18.01.2022).
44. A. Broder, S. Glassman, M. Manasse, G. Zweig. Syntactic Clustering of the Web // Comput. Netw. ISDN Syst. 1997. Vol. 29. P. 1157–1166. URL: https://doi.org/10.1016/S0169-7552(97)00031-7 (last accessed: 18.01.2022).
45. D. Fetterly, M. Manasse, M. Najor, et al. A Large-Scale Study of the Evolution of Web Pages // ACM. 2003. P. 669–678. URL: https://doi.org/10.1145/775152.775246 (last accessed: 18.01.2022).
46. Djulaga Hadzic, Nermin Sarajlic. Methodology for fuzzy duplicate record identification based on the semantic-syntactic information of similarity // Journal of King Saud University-Computer and Information Sciences. 2020. URL: https://doi.org/10.1016/j.jksuci.2018.05.001 (last accessed: 18.01.2022).
47. M. A. Hernandez, S. J. Stolfo. Real-world Data is Dirty: Data Cleansing and the Merge/Purge Problem // Data Mining and Knowledge Discovery. 1998. URL: http://dx.doi.org/10.1023/A:1009761603038 (last accessed: 18.01.2022).
48. H. P. Luhn. The automatic creation of literature abstracts // IBM J. Res. Dev. 1958. №2 (2) URL: http://dx.doi.org/10.1147/rd.22.0159 (last accessed: 18.01.2022).
49. Ruslan Mitkov. Automatic abstracting in a limited domain // Proceedings of PACFoCoL I (1993): Pacific Asia Conference on Formal and Computational Linguistics. 1993. https://waseda.repo.nii.ac.jp/?action=repository_action_common_download&attribute_id=101&file_no=1&item_id=28418&item_no=1 (last accessed: 18.01.2022).
50. Y. D. Prabowo, A. I. Kristijantoro, H. L. H. S. Warnars, W. Budiharto. Systematic literature review on abstractive text summarization using kitchenham method // ICIC Express Letters, Part B: Applications. 2021. №11. URL: https://doi.org/10.24507/icicelb.12.11.1075 (last accessed: 18.01.2022).
51. Abdelkrime Aries, Djamel Eddine, Zegour Khaled, Walid Hidouci. AllSummarizer system at MultiLing 2015: Multilingual single and multi-document summarization // Proceedings of the SIGDIAL 2015 Conference. 2015. URL: http://dx.doi.org/10.18653/v1/W15-4634 (last accessed: 18.01.2022).
52. A. Esteva, A. Kale, R. Paulus et al. COVID-19 information retrieval with deep-learning based semantic search, question answering, and abstractive summarization // npj Digital Medicine. 2021. URL: https://doi.org/10.1038/s41746-021-00437-0 (last accessed: 18.01.2022).
53. D. Inouye, J. K. Kalita. Comparing Twitter Summarization Algorithms for Multiple Post Summaries // 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third International Conference on Social Computing. 2011. URL: https://doi.org/10.1109/PASSAT/SocialCom.2011.31 (last accessed: 18.01.2022).
54. Y. Zhang, Y. Zhou, J. T. Yao. Feature Extraction with TF-IDF and Game-Theoretic Shadowed Sets // Information Processing and Management of Uncertainty in Knowledge-Based Systems. IPMU 2020. Communications in Computer and Information Science. 2020. URL: https://doi.org/10.1007/978-3-030-50146-4_53 (last accessed: 18.01.2022).
55. L. Vanderwende, H. Suzuki, C. Brockett, A. Nenkova. Beyond SumBasic: Task-focused summarization with sentence simplification and lexical expansion // Information Processing & Management. 2007. URL: https://doi.org/10.1016/j.ipm.2007.01.023 (last accessed: 18.01.2022).
56. Coffman, E. G., Z. Liu, Richard R. Weber. Optimal Robot Scheduling for Web Search Engines // Journal of Scheduling. 1998. URL: https://doi.org/10.1002/(SICI)1099-1425(199806)1:1%3C15::AID-JOS3%3E3.0.CO;2-K (last accessed: 18.01.2022).
57. Junghoo Cho, Hector Garcia-Molina. Synchronizing a Database to Improve Freshness // Proceedings of the International Conference on Management of Data (SIGMOD). 2000. URL: http://dx.doi.org/10.1145/342009.335391 (last accessed: 18.01.2022).
58. Ka Cheung Sia, Junghoo Cho, Hyun-Kyu Cho. Efficient Monitoring Algorithm for Fast News Alert // IEEE Transaction of Knowledge and Data Engineering. 2007. URL: https://doi.org/10.1109/TKDE.2007.1041 (last accessed: 18.01.2022).
59. Junghoo Cho, Hector Garcia-Molina. Estimating Frequency of Change // ACM Transactions on Internet Technology. 2000. URL: https://doi.org/10.1145/857166.857170 (last accessed: 18.01.2022).
60. Utkarsh Upadhyay, Róbert Busa-Fekete, Wojciech Kotlowski, Dávid Pál, Balazs Szorenyi. Learning to Crawl. Proceedings of the AAAI Conference on Artificial Intelligence. 2020. URL: https://doi.org/10.1609/aaai.v34i04.6067 (last accessed: 18.01.2022).
61. Craig E Wills, Mikhail Mikhailov. Towards a better understanding of Web resources and server responses for improved caching // Computer Networks. 1999. URL: https://doi.org/10.1016/S1389-1286(99)00037-7 (last accessed: 18.01.2022).
62. Alec Wolman, Geoffrey M. Voelker, Nitin Sharma, Neal Cardwell, Anna Karlin, Henry M. Levy. On the scale and performance of cooperative Web proxy caching // ACM SIGOPS Operating Systems Review. 2000. №2. URL: https://doi.org/10.1145/346152.346166 (last accessed: 18.01.2022).
63. Konstantin Avrachenkov, Kishor Patil, Gugan Thoppe. Online algorithms for estimating change rates of web pages // Performance Evaluation. 2022. URL: https://doi.org/10.1016/j.peva.2021.102261 (last accessed: 18.01.2022).
64. Sergey Brin, Lawrence Page. Reprint of: The anatomy of a large-scale hypertextual web search engine // Computer Networks. 2012. URL: https://doi.org/10.1016/j.comnet.2012.10.007 (last accessed: 18.01.2022).
65. Jie Zhang, Yuan Wang, Julita Vassileva. SocConnect: A personalized social network aggregator and recommender // Information Processing & Management. 2013. URL: https://doi.org/10.1016/j.ipm.2012.07.006 (last accessed: 18.01.2022).
66. Gaou Salma, Kamal Eddine el Kadiri, Corneliu Buraga. Representation Modeling Persona by using Ontologies: Vocabulary Persona // International Journal of Advanced Computer Science and Applications. 2013. URL: https://dx.doi.org/10.14569/IJACSA.2013.040829 (last accessed: 18.01.2022).
67. Zhen Qin, Yicheng Cheng, Zhe Zhao, Zhe Chen, Donald Metzler, Jingzheng Qin. Multitask Mixture of Sequential Experts for User Activity Streams // Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD '20). 2020. URL: https://doi.org/10.1145/3394486.3403359 (last accessed: 18.01.2022).
68. Cosmin Grozea, Dumitru-Clementin Cercel, Cristian Onose, Stefan Trausan-Matu. Atlas: News aggregation service // 16th RoEduNet Conference: Networking in Education and Research (RoEduNet). 2017. URL: http://dx.doi.org/10.1109/ROEDUNET.2017.8123756 (last accessed: 18.01.2022).
69. L. Richardson, M. Amundsen, S. Ruby. RESTful Web APIs: Services for a Changing World / O'Reilly Media, Inc. 2013.-P. 406
70. M. Lutz. Learning Python, Fifth Edition / O'Reilly Media. 2013.-P. 1594.
71. M. Grinberg. Flask Web Development: Developing Web Applications with Python / O'Reilly Media. 2018. – 291 p.
72. M. D. Silva, H. L. Tavares. Redis Essentials. Harness the power of Redis to integrate and manage your projects efficiently / Packt Publishing. 2015.-P. 230.
73. Joel Murach. Murach's MySQL (3rd Edition) / Mike Murach & Associates. 2019.-P. 628.
74. Shyam Seshadri. Angular: Up and Running: Learning Angular, Step by Step / O'Reilly Media. 2018.-P. 300.
75. F. Hamborg, N. Meuschke, B. Gipp. Matrix-based news aggregation: exploring different news perspectives // Proceedings of the 17th ACM/IEEE Joint Conference on Digital Libraries. 2017. URL: http://dx.doi.org/10.1109/JCDL.2017.7991561 (last accessed: 18.01.2022).
76. Apache Lucene Core [Website]. URL: https://lucene.apache.org/core/ (last accessed: 18.01.2022).
77. Alaidine Ben Ayed, Ismaïl Biskri, Jean Meunier. An End-to-End Efficient Lucene-Based Framework of Document/ Information Retrieval // International Journal of Information Retrieval Research. 2021. URL: http://dx.doi.org/10.4018/IJIRR.289950 (last accessed: 18.01.2022).
78. David Blei, Andrew Ng, Michael Jordan. Latent Dirichlet Allocation // The Journal of Machine Learning Research. 2001. URL: https://www.researchgate.net/publication/221620547 (last accessed: 18.01.2022).
79. G. Paliouras, A. Mouzakidis, V. Moustakas, C. Skourlas. PNS: A Personalized News Aggregator on the Web // Computer Science. 2008. URL: http://dx.doi.org/10.1007/978-3-540-77471-6_10 (last accessed: 18.01.2022).
80. Welcome to PServer [Website]. URL: http://www.pserver-project.org (last accessed: 18.01.2022).
81. Lawrence Page, Sergey Brin, Rajeev Motwani, Terry Winograd. The PageRank Citation Ranking: Bringing Order to the Web // Stanford InfoLab. 1999. URL: http://ilpubs.stanford.edu:8090/422/ (last accessed: 18.01.2022).
82. Maarten van Steen, Andrew Tanenbaum. A brief introduction to distributed systems // Computing. 2016. № 98 (10). URL: https://www.researchgate.net/publication/306241722_A_brief_introduction_to_distributed_systems (last accessed: 18.01.2022).
83. Maarten van Steen, Andrew Tanenbaum. Distributed Systems. / CreateSpace Independent Publishing Platform. 2017 – 596 p.
84. George Coulouris, Jean Dollimore, Tim Kindberg. Distributed systems. Concepts and design. Fifth edition. / Addison Wesley. 2012 – 1047 p.
85. Mark Richards, Neal Ford. Fundamentals of Software Architecture / O'Reilly Media, Inc. 2020 – 400 p.
86. Martin Kleppmann. Designing Data-Intensive Applications. The Big Ideas Behind Reliable, Scalable, and Maintainable Systems / O'Reilly Media. 2017-616 p.
87. Kiryanov D. A. — Hybrid categorical expert system for use in content aggregation // Software systems and computational methods. 2021. № 4. URL: https://dx.doi.org/10.7256/2454-0714.2021.4.37019 (last accessed: 18.01.2022).
88. Zhao J. T., Jing S. Y., Jiang L.Z. Management of API Gateway Based on Micro-service Architecture // Journal of Physics: Conference Series. 2018. URL: https://doi.org/10.1088/1742-6596/1087/3/032032 (last accessed: 18.01.2022).
89. Xianyu Zuo, Yuehan Su, Qianqian Wang, Yi Xie. An API gateway design strategy optimized for persistence and coupling // Advances in Engineering Software. 2020. URL: https://doi.org/10.1016/j.advengsoft.2020.102878 (last accessed: 18.01.2022).
90. Yang Dawei, Gao Yang, He Wei, Li Kai. Design and Achievement of Security Mechanism of API Gateway Platform Based on Microservice Architecture // J. Phys.: Conf. Ser. 1738 012046. 2021. URL: https://doi.org/10.1088/1742-6596/1738/1/012046 (last accessed: 18.01.2022).
91. Jabbar Jahanzeb, JunSheng Wu, Weigang Li, Urooj Iqra. Implementation of Search Engine with Lucene // Document Management System. 2019. URL: https://dx.doi.org/10.1109/ICECE48499.2019.9058515 (last accessed: 18.01.2022).
92. Balipa Mamatha, Ramasamy Balasubramani. Search Engine using Apache Lucene // International Journal of Computer Applications. 2015. URL: http://dx.doi.org/10.5120/ijca2015906476 (last accessed: 18.01.2022).
93. Artem Chebotko, Andrey Kashlev, Shiyong Lu. A Big Data Modeling Methodology for Apache Cassandra // 2015 IEEE International Congress on Big Data (BigData Congress). 2015. URL: https://dx.doi.org/10.1109/BigDataCongress.2015.41 (last accessed: 18.01.2022).
94. Dimitris Uzunidis, Karkazis Panagiotis, Chara Roussou, Charalampos Patrikakis, Leligou Helen. Intelligent Performance Prediction: The Use Case of a Hadoop Cluster // Electronics. 2021. URL: https://doi.org/10.3390/electronics10212690 (last accessed: 18.01.2022).
95. Merceedi, K. J., Sabry, N. A. A Comprehensive Survey for Hadoop Distributed File System // Asian Journal of Research in Computer Science. 2021. URL: https://doi.org/10.9734/ajrcos/2021/v11i230260 (last accessed: 18.01.2022).
References
1. August 2021 Web Server Survey // Netcraft News [Website]. 2021. URL: https://news.netcraft.com/archives/2021/08/25/august-2021-web-server-survey.html (last accessed: 18.01.2022).
2. Maurice de Kunder. The size of the World Wide Web (The Internet) // WorldWideWebSize.com. Daily Estimated Size of The World Wide Web [Website]. 2021. URL: https://www.worldwidewebsize.com (last accessed: 18.01.2022).
3. World Internet Users and 2021 Population Stats // Internet World Stats [Website]. 2021. URL: https://www.internetworldstats.com/stats.htm (last accessed: 18.01.2022).
4. G. Paliouras, A. Mouzakidis, C. Skourlas, M. Virvou, C. L. Jain. PNS: A Personalized News Aggregator on the Web // Intelligent Interactive Systems in Knowledge-Based Environments. 2008. URL: https://doi.org/10.1007/978-3-540-77471-6_10 (last accessed: 18.01.2022).
5. David Reinsel, John Gantz, John Rydning. The Digitization of the World – From Edge to Core // An IDC White Paper. 2018. 28p. URL: https://www.seagate.com/files/www-content/our-story/trends/files/idc-seagate-dataage-whitepaper.pdf (last accessed: 18.01.2022).
6. S. Chowdhury, M. Landoni. News aggregator services: user expectations and experience // Online Information Review. 2006. URL: https://doi.org/10.1108/14684520610659157 (last accessed: 18.01.2022).
7. Khramova N. N. Spetsifikatsiya generatsii novostei cherez RSS na primere raboty agregatora Yandeks. Novosti // Znak: problemnoe pole mediaobrazovaniya. 2015. №3 (17). URL: https://cyberleninka.ru/article/n/spetsifikatsiya-generatsii-novostey-cherez-rss-na-primere-raboty-agregatora-yandeks-novosti (last accessed: 18.01.2022).
8. Shagdarova B. B. Novostnye agregatory v internete // Vestnik BGU. Yazyk, literatura, kul'tura. 2017. №1. URL: https://cyberleninka.ru/article/n/novostnye-agregatory-v-internete (last accessed: 18.01.2022).
9. Masenkov V. V. Agregatsiya kontenta v Rossii i v mire: est' li budushchee u novostnoi agregatsii? [Elektronnyi resurs] // Media-kommunikatsionnyi forum RIW 15, 21–23 oktyabrya 2015, Rossiya, Moskva, Ekspotsentr. URL: http://files.runet-id.com/2015/riw/presentations/22oct.riw15-green-1--masenkov.pdf (last accessed: 18.01.2022).
10. Ivan Bushukhin. "Yandeks" izmenil politiku raboty s ob''yavleniyami o nedvizhimosti. [Website] // RBK Nedvizhimost'. 2014. URL: https://realty.rbc.ru/news/577d23ca9a7947a78ce91950 (last accessed: 18.01.2022).
11. RSS 2.0 Specification. [Website] // RSS Advisory Board. URL: https://www.rssboard.org/rss-specification (last accessed: 18.01.2022).
12. Joshua Grossnickle, Todd Board, Brian Pickens, Mike Bellmont. RSS–Crossing into the Mainstream. // Yahoo! 2005. – 12 p. URL: https://content.marketingsherpa.com/heap/cs/rsscharts/7.pdf (last accessed: 18.01.2022).
13. K. Sundaramoorthy, R. Durga, S. Nagadarshini. NewsOne — An Aggregation System for News Using Web Scraping Method // International Conference on Technical Advancements in Computers and Communications (ICTACC). 2017. URL: http://dx.doi.org/10.1109/ICTACC.2017.43 (last accessed: 18.01.2022).
14. Moskalenko A. A., Laponina O. R., Sukhomlin V. A. Developing a Web Scraping Application with Bypass Blocking // Modern Information Technology and IT-education. 2019. №2. URL: https://doi.org/10.25559/SITITO.15.201902.413-420 (last accessed: 18.01.2022).
15. YML and CSV formats [Website]. // Yandex Support. URL: https://yandex.com/support/partnermarket/export/yml.html#yml-format (last accessed: 18.01.2022).
16. Job aggregator in the USA, post jobs on Jooble [Website]. URL: https://jooble.org/partner/ppc (last accessed: 18.01.2022).
17. Alaa Mohamed, Marwan Ibrahim, Mayar Yasser, Mohamed Ayman, Menna Gamil, Walaa Hassan. News Aggregator and Efficient Summarization System. // International Journal of Advanced Computer Science and Applications (IJACSA). 2020. URL: http://dx.doi.org/10.14569/IJACSA.2020.0110677 (last accessed: 18.01.2022).
18. A. Jabbar, S. Iqbal, M. I. Tamimy. Empirical evaluation and study of text stemming algorithms // Artificial Intelligence Review. 2020. URL: https://doi.org/10.1007/s10462-020-09828-3 (last accessed: 18.01.2022).
19. T. Bergmanis, S. Goldwater. Context sensitive neural lemmatization with Lematus // Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. URL: http://dx.doi.org/10.18653/v1/N18-1126 (last accessed: 18.01.2022).
20. G. Salton, C. Buckley. Term-weighting approaches in automatic text retrieval // Information Processing & Management. 1988. URL: https://doi.org/10.1016/0306-4573(88)90021-0 (last accessed: 18.01.2022).
21. Y. Zhang, Y. Zhou, J. T. Yao. Feature Extraction with TF-IDF and Game-Theoretic Shadowed Sets // Information Processing and Management of Uncertainty in Knowledge-Based Systems. IPMU 2020. Communications in Computer and Information Science. 2020. URL: https://doi.org/10.1007/978-3-030-50146-4_53 (last accessed: 18.01.2022).
22. Yuliya Kontsewaya, Evgeniy Antonov, Alexey Artamonov. Evaluating the Effectiveness of Machine Learning Methods for Spam Detection // Procedia Computer Science. 2021. URL: https://doi.org/10.1016/j.procs.2021.06.056 (last accessed: 18.01.2022).
23. Zelenkov Yu. G., Segalovich I. V. Sravnitel'nyi analiz metodov opredeleniya nechetkikh dublikatov dlya Web-dokumentov // Trudy 9-oi Vserossiiskoi nauchnoi konferentsii «Elektronnye biblioteki: perspektivnye metody i tekhnologii, elektronnye kollektsii» RCDL’2007: Sb. rabot uchastnikov konkursa.-T. 1.-Pereslavl'-Zalesskii: «Universitet goroda Pereslavlya», 2007.-S. 166–174. URL: http://elib.ict.nsc.ru/jspui/bitstream/ICT/1233/1/segal_65_v1.pdf (last accessed: 18.01.2022).
24. Daniel López-Sánchez, Angélica González Arrieta, Juan M. Corchado. Visual content-based web page categorization with deep transfer learning and metric learning // Neurocomputing. 2019. URL: https://doi.org/10.1016/j.neucom.2018.08.086 (last accessed: 18.01.2022).
25. Adrita Barua, Omar Sharif, Mohammed Moshiul Hoque. Multi-class Sports News Categorization using Machine Learning Techniques: Resource Creation and Evaluation // Procedia Computer Science. 2021. URL: https://doi.org/10.1016/j.procs.2021.11.002 (last accessed: 18.01.2022).
26. Abdelkrime Aries, Djamel eddine Zegour, Walid Khaled Hidouci. Automatic text summarization: What has been done and what has to be done. // ArXiv. 2019. URL: https://arxiv.org/pdf/1904.00688.pdf (last accessed: 18.01.2022).
27. V. Shkapenyuk, T. Suel. Design and implementation of a high-performance distributed Web crawler //Proceedings of the 18th International Conference on Data Engineering. San Jose, CA, USA. 2002. URL: https://doi.org/10.1109/ICDE.2002.994750 (last accessed: 18.01.2022).
28. J. Edwards, K. S. McCurley, J. A. Tomlin. An adaptive model for optimizing performance of an incremental web crawler // Proceedings of the 10th International World Wide Web Conference. 2001. URL: http://dx.doi.org/10.1145/371920.371960 (last accessed: 18.01.2022).
29. P. Boldi, B. Codenotti, M. Santini, and S. Vigna. UbiCrawler: A scalable fully distributed web crawler // Software — Practice & Experience. 2004. № 8, pp. 711–726. URL: https://doi.org/10.1002/spe.587 (last accessed: 18.01.2022).
30. Allan Heydon, Marc Najork. Mercator: A scalable, extensible Web crawler // World Wide Web 2. Palo Alto, CA, USA. 1999. №4. URL: https://doi.org/10.1023/A:1019213109274 (last accessed: 18.01.2022).
31. Salim Khalil, Mohamed Fakir. RCrawler: An R package for parallel web crawling and scraping // SoftwareX. 2017. URL: https://doi.org/10.1016/j.softx.2017.04.004 (last accessed: 18.01.2022).
32. Ida Bifulco, Stefano Cirillo, Christian Esposito, Roberta Guadagni, Giuseppe Polese. An intelligent system for focused crawling from Big Data sources // Expert Systems with Applications. 2021. URL: https://doi.org/10.1016/j.eswa.2021.115560 (last accessed: 18.01.2022).
33. Hyunjoong Kim, Han Kyul Kim, Sungzoon Cho. Improving spherical k-means for document clustering: Fast initialization, sparse centroid projection, and efficient cluster labeling // Expert Systems with Applications. 2020. URL: https://doi.org/10.1016/j.eswa.2020.113288 (last accessed: 18.01.2022).
34. Bifulco, I., Cirillo, S. Discovery multiple data structures in big data through global optimization and clustering methods // Proceedings of the 22nd international conference information visualisation. 2018. URL: http://dx.doi.org/10.1109/iV.2018.00030 (last accessed: 18.01.2022).
35. Christopher Olston, Marc Najork. Web Crawling // Foundations and Trends. 2010. №3. URL: http://dx.doi.org/10.1561/1500000017 (last accessed: 18.01.2022).
36. M. Rostanski, K. Grochla, A. Seman. Evaluation of highly available and fault-tolerant middleware clustered architectures using RabbitMQ // Proc. Of Federated Conference on Computer Science and Information Systems. 2014. URL: http://dx.doi.org/10.15439/978-83-60810-58-3 (last accessed: 18.01.2022).
37. Nguyen C. N., Hwang S., Jik-Soo Kim. Making a case for the on-demand multiple distributed message queue system in a Hadoop cluster // Cluster Computing. 2017. №20. URL: https://doi.org/10.1007/s10586-017-1031-0 (last accessed: 18.01.2022).
38. High-Performance Load Balancing [Website] URL: https://www.nginx.com/products/nginx/load-balancing/ (last accessed: 18.01.2022).
39. Bobrov A. V., Rubashenkov A. M. Nastroika proksi-servera Nginx // Academy. 2019. №5 (44). URL: https://cyberleninka.ru/article/n/nastroyka-proksi-servera-nginx (last accessed: 18.01.2022).
40. HAProxy Technologies. The World’s Fastest and Most Widely Used Software Load Balancer [Website]. URL: https://www.haproxy.com/ (last accessed: 18.01.2022).
41. Elastic Load Balancing [Website]. URL: https://aws.amazon.com/elasticloadbalancing/ (last accessed: 18.01.2022).
42. Cloud Load Balancing. High-performance, scalable load balancing on Google Cloud Platform [Website]. URL: https://cloud.google.com/load-balancing/ (last accessed: 18.01.2022).
43. U. Manber. Finding Similar Files in a Large File System // Proc. USENIX WINTER Technical Conference. 1994. URL: https://www.cs.arizona.edu/sites/default/files/TR93-33.pdf (last accessed: 18.01.2022).
44. A. Broder, S. Glassman, M. Manasse, G. Zweig. Syntactic Clustering of the Web // Comput. Netw. ISDN Syst. 1997. Vol. 29. P. 1157–1166. URL: https://doi.org/10.1016/S0169-7552(97)00031-7 (last accessed: 18.01.2022).
45. D. Fetterly, M. Manasse, M. Najor, et al. A Large-Scale Study of the Evolution of Web Pages // ACM. 2003. P. 669–678. URL: https://doi.org/10.1145/775152.775246 (last accessed: 18.01.2022).
46. Djulaga Hadzic, Nermin Sarajlic. Methodology for fuzzy duplicate record identification based on the semantic-syntactic information of similarity // Journal of King Saud University-Computer and Information Sciences. 2020. URL: https://doi.org/10.1016/j.jksuci.2018.05.001 (last accessed: 18.01.2022).
47. M. A. Hernandez, S. J. Stolfo. Real-world Data is Dirty: Data Cleansing and the Merge/Purge Problem // Data Mining and Knowledge Discovery. 1998. URL: http://dx.doi.org/10.1023/A:1009761603038 (last accessed: 18.01.2022).
48. H. P. Luhn. The automatic creation of literature abstracts // IBM J. Res. Dev. 1958. №2 (2) URL: http://dx.doi.org/10.1147/rd.22.0159 (last accessed: 18.01.2022).
49. Ruslan Mitkov. Automatic abstracting in a limited domain // Proceedings of PACFoCoL I (1993): Pacific Asia Conference on Formal and Computational Linguistics. 1993. https://waseda.repo.nii.ac.jp/?action=repository_action_common_download&attribute_id=101&file_no=1&item_id=28418&item_no=1 (last accessed: 18.01.2022).
50. Y. D. Prabowo, A. I. Kristijantoro, H. L. H. S. Warnars, W. Budiharto. Systematic literature review on abstractive text summarization using kitchenham method // ICIC Express Letters, Part B: Applications. 2021. №11. URL: https://doi.org/10.24507/icicelb.12.11.1075 (last accessed: 18.01.2022).
51. Abdelkrime Aries, Djamel Eddine, Zegour Khaled, Walid Hidouci. AllSummarizer system at MultiLing 2015: Multilingual single and multi-document summarization // Proceedings of the SIGDIAL 2015 Conference. 2015. URL: http://dx.doi.org/10.18653/v1/W15-4634 (last accessed: 18.01.2022).
52. A. Esteva, A. Kale, R. Paulus et al. COVID-19 information retrieval with deep-learning based semantic search, question answering, and abstractive summarization // npj Digital Medicine. 2021. URL: https://doi.org/10.1038/s41746-021-00437-0 (last accessed: 18.01.2022).
53. D. Inouye, J. K. Kalita. Comparing Twitter Summarization Algorithms for Multiple Post Summaries // 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third International Conference on Social Computing. 2011. URL: https://doi.org/10.1109/PASSAT/SocialCom.2011.31 (last accessed: 18.01.2022).
54. Y. Zhang, Y. Zhou, J. T. Yao. Feature Extraction with TF-IDF and Game-Theoretic Shadowed Sets // Information Processing and Management of Uncertainty in Knowledge-Based Systems. IPMU 2020. Communications in Computer and Information Science. 2020. URL: https://doi.org/10.1007/978-3-030-50146-4_53 (last accessed: 18.01.2022).
55. L. Vanderwende, H. Suzuki, C. Brockett, A. Nenkova. Beyond SumBasic: Task-focused summarization with sentence simplification and lexical expansion // Information Processing & Management. 2007. URL: https://doi.org/10.1016/j.ipm.2007.01.023 (last accessed: 18.01.2022).
56. Coffman, E. G., Z. Liu, Richard R. Weber. Optimal Robot Scheduling for Web Search Engines // Journal of Scheduling. 1998. URL: https://doi.org/10.1002/(SICI)1099-1425(199806)1:1%3C15::AID-JOS3%3E3.0.CO;2-K (last accessed: 18.01.2022).
57. Junghoo Cho, Hector Garcia-Molina. Synchronizing a Database to Improve Freshness // Proceedings of the International Conference on Management of Data (SIGMOD). 2000. URL: http://dx.doi.org/10.1145/342009.335391 (last accessed: 18.01.2022).
58. Ka Cheung Sia, Junghoo Cho, Hyun-Kyu Cho. Efficient Monitoring Algorithm for Fast News Alert // IEEE Transaction of Knowledge and Data Engineering. 2007. URL: https://doi.org/10.1109/TKDE.2007.1041 (last accessed: 18.01.2022).
59. Junghoo Cho, Hector Garcia-Molina. Estimating Frequency of Change // ACM Transactions on Internet Technology. 2000. URL: https://doi.org/10.1145/857166.857170 (last accessed: 18.01.2022).
60. Utkarsh Upadhyay, Róbert Busa-Fekete, Wojciech Kotlowski, Dávid Pál, Balazs Szorenyi. Learning to Crawl. Proceedings of the AAAI Conference on Artificial Intelligence. 2020. URL: https://doi.org/10.1609/aaai.v34i04.6067 (last accessed: 18.01.2022).
61. Craig E Wills, Mikhail Mikhailov. Towards a better understanding of Web resources and server responses for improved caching // Computer Networks. 1999. URL: https://doi.org/10.1016/S1389-1286(99)00037-7 (last accessed: 18.01.2022).
62. Alec Wolman, Geoffrey M. Voelker, Nitin Sharma, Neal Cardwell, Anna Karlin, Henry M. Levy. On the scale and performance of cooperative Web proxy caching // ACM SIGOPS Operating Systems Review. 2000. №2. URL: https://doi.org/10.1145/346152.346166 (last accessed: 18.01.2022).
63. Konstantin Avrachenkov, Kishor Patil, Gugan Thoppe. Online algorithms for estimating change rates of web pages // Performance Evaluation. 2022. URL: https://doi.org/10.1016/j.peva.2021.102261 (last accessed: 18.01.2022).
64. Sergey Brin, Lawrence Page. Reprint of: The anatomy of a large-scale hypertextual web search engine // Computer Networks. 2012. URL: https://doi.org/10.1016/j.comnet.2012.10.007 (last accessed: 18.01.2022).
65. Jie Zhang, Yuan Wang, Julita Vassileva. SocConnect: A personalized social network aggregator and recommender // Information Processing & Management. 2013. URL: https://doi.org/10.1016/j.ipm.2012.07.006 (last accessed: 18.01.2022).
66. Gaou Salma, Kamal Eddine el Kadiri, Corneliu Buraga. Representation Modeling Persona by using Ontologies: Vocabulary Persona // International Journal of Advanced Computer Science and Applications. 2013. URL: https://dx.doi.org/10.14569/IJACSA.2013.040829 (last accessed: 18.01.2022).
67. Zhen Qin, Yicheng Cheng, Zhe Zhao, Zhe Chen, Donald Metzler, Jingzheng Qin. Multitask Mixture of Sequential Experts for User Activity Streams // Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD '20). 2020. URL: https://doi.org/10.1145/3394486.3403359 (last accessed: 18.01.2022).
68. Cosmin Grozea, Dumitru-Clementin Cercel, Cristian Onose, Stefan Trausan-Matu. Atlas: News aggregation service // 16th RoEduNet Conference: Networking in Education and Research (RoEduNet). 2017. URL: http://dx.doi.org/10.1109/ROEDUNET.2017.8123756 (last accessed: 18.01.2022).
69. L. Richardson, M. Amundsen, S. Ruby. RESTful Web APIs: Services for a Changing World / O'Reilly Media, Inc. 2013.-P. 406
70. M. Lutz. Learning Python, Fifth Edition / O'Reilly Media. 2013.-P. 1594.
71. M. Grinberg. Flask Web Development: Developing Web Applications with Python / O'Reilly Media. 2018. – 291 p.
72. M. D. Silva, H. L. Tavares. Redis Essentials. Harness the power of Redis to integrate and manage your projects efficiently / Packt Publishing. 2015.-P. 230.
73. Joel Murach. Murach's MySQL (3rd Edition) / Mike Murach & Associates. 2019.-P. 628.
74. Shyam Seshadri. Angular: Up and Running: Learning Angular, Step by Step / O'Reilly Media. 2018.-P. 300.
75. F. Hamborg, N. Meuschke, B. Gipp. Matrix-based news aggregation: exploring different news perspectives // Proceedings of the 17th ACM/IEEE Joint Conference on Digital Libraries. 2017. URL: http://dx.doi.org/10.1109/JCDL.2017.7991561 (last accessed: 18.01.2022).
76. Apache Lucene Core [Website]. URL: https://lucene.apache.org/core/ (last accessed: 18.01.2022).
77. Alaidine Ben Ayed, Ismaïl Biskri, Jean Meunier. An End-to-End Efficient Lucene-Based Framework of Document/ Information Retrieval // International Journal of Information Retrieval Research. 2021. URL: http://dx.doi.org/10.4018/IJIRR.289950 (last accessed: 18.01.2022).
78. David Blei, Andrew Ng, Michael Jordan. Latent Dirichlet Allocation // The Journal of Machine Learning Research. 2001. URL: https://www.researchgate.net/publication/221620547 (last accessed: 18.01.2022).
79. G. Paliouras, A. Mouzakidis, V. Moustakas, C. Skourlas. PNS: A Personalized News Aggregator on the Web // Computer Science. 2008. URL: http://dx.doi.org/10.1007/978-3-540-77471-6_10 (last accessed: 18.01.2022).
80. Welcome to PServer [Website]. URL: http://www.pserver-project.org (last accessed: 18.01.2022).
81. Lawrence Page, Sergey Brin, Rajeev Motwani, Terry Winograd. The PageRank Citation Ranking: Bringing Order to the Web // Stanford InfoLab. 1999. URL: http://ilpubs.stanford.edu:8090/422/ (last accessed: 18.01.2022).
82. Maarten van Steen, Andrew Tanenbaum. A brief introduction to distributed systems // Computing. 2016. № 98 (10). URL: https://www.researchgate.net/publication/306241722_A_brief_introduction_to_distributed_systems (last accessed: 18.01.2022).
83. Maarten van Steen, Andrew Tanenbaum. Distributed Systems. / CreateSpace Independent Publishing Platform. 2017 – 596 p.
84. George Coulouris, Jean Dollimore, Tim Kindberg. Distributed systems. Concepts and design. Fifth edition. / Addison Wesley. 2012 – 1047 p.
85. Mark Richards, Neal Ford. Fundamentals of Software Architecture / O'Reilly Media, Inc. 2020 – 400 p.
86. Martin Kleppmann. Designing Data-Intensive Applications. The Big Ideas Behind Reliable, Scalable, and Maintainable Systems / O'Reilly Media. 2017-616 p.
87. Kiryanov D. A. — Hybrid categorical expert system for use in content aggregation // Software systems and computational methods. 2021. № 4. URL: https://dx.doi.org/10.7256/2454-0714.2021.4.37019 (last accessed: 18.01.2022).
88. Zhao J. T., Jing S. Y., Jiang L.Z. Management of API Gateway Based on Micro-service Architecture // Journal of Physics: Conference Series. 2018. URL: https://doi.org/10.1088/1742-6596/1087/3/032032 (last accessed: 18.01.2022).
89. Xianyu Zuo, Yuehan Su, Qianqian Wang, Yi Xie. An API gateway design strategy optimized for persistence and coupling // Advances in Engineering Software. 2020. URL: https://doi.org/10.1016/j.advengsoft.2020.102878 (last accessed: 18.01.2022).
90. Yang Dawei, Gao Yang, He Wei, Li Kai. Design and Achievement of Security Mechanism of API Gateway Platform Based on Microservice Architecture // J. Phys.: Conf. Ser. 1738 012046. 2021. URL: https://doi.org/10.1088/1742-6596/1738/1/012046 (last accessed: 18.01.2022).
91. Jabbar Jahanzeb, JunSheng Wu, Weigang Li, Urooj Iqra. Implementation of Search Engine with Lucene // Document Management System. 2019. URL: https://dx.doi.org/10.1109/ICECE48499.2019.9058515 (last accessed: 18.01.2022).
92. Balipa Mamatha, Ramasamy Balasubramani. Search Engine using Apache Lucene // International Journal of Computer Applications. 2015. URL: http://dx.doi.org/10.5120/ijca2015906476 (last accessed: 18.01.2022).
93. Artem Chebotko, Andrey Kashlev, Shiyong Lu. A Big Data Modeling Methodology for Apache Cassandra // 2015 IEEE International Congress on Big Data (BigData Congress). 2015. URL: https://dx.doi.org/10.1109/BigDataCongress.2015.41 (last accessed: 18.01.2022).
94. Dimitris Uzunidis, Karkazis Panagiotis, Chara Roussou, Charalampos Patrikakis, Leligou Helen. Intelligent Performance Prediction: The Use Case of a Hadoop Cluster // Electronics. 2021. URL: https://doi.org/10.3390/electronics10212690 (last accessed: 18.01.2022).
95. Merceedi, K. J., Sabry, N. A. A Comprehensive Survey for Hadoop Distributed File System // Asian Journal of Research in Computer Science. 2021. URL: https://doi.org/10.9734/ajrcos/2021/v11i230260 (last accessed: 18.01.2022).
Результаты процедуры рецензирования статьи
Рецензия скрыта по просьбе автора
|














