|
Кибернетика и программирование
Правильная ссылка на статью:
Бакаев И.И.
Разработка алгоритма стемминга для слов узбекского языка
// Кибернетика и программирование.
2021. № 1.
С. 1-12.
DOI: 10.25136/2644-5522.2021.1.35847 URL: https://nbpublish.com/library_read_article.php?id=35847
Разработка алгоритма стемминга для слов узбекского языка
Бакаев Илхом Изатович
старший научный сотрудник, Научно-инновационный центр информационно-коммуникационных технологий при ТУИТ
100124, Узбекистан, республика 100124, г. Ташкент, ул. М-В буз-2, 17А
Bakaev Ilkhom Izatovich
Senior Scientific Associate, Science and Innovation Center for Information and Communication Technologies at the Tashkent University of Information Technologies
100124, Uzbekistan, respublika 100124, g. Tashkent, ul. M-V buz-2, 17A

|
bakayev2101@gmail.com
|
|
 |
|
DOI: 10.25136/2644-5522.2021.1.35847
Дата направления статьи в редакцию:
01-06-2021
Дата публикации:
09-06-2021
Аннотация:
Автоматическая обработка неструктурированных текстов на естественных языках является одной из актуальных проблем компьютерного анализа и синтеза текстов. В ней можно отдельно выделить задачу нормализации текстов, обычно, подразумевающую выполнение таких процессов, как токенизация, стемминг и лемматизация. Существующие алгоритмы стемминга в большинстве ориентированы на синтетические языки, в которых преобладает формообразование с использованием морфем. Узбекский язык представляет собой пример агглютинативного языка, отличающегося полисемантичностью аффиксальных и служебных морфем. Хотя узбекский язык имеет множество отличий, например, от английского языка, тем не менее он вполне успешно поддается обработке алгоритмами стемминга. Примеры эффективной реализации алгоритмов стемминга для узбекского языка, до настоящего времени, практически не встречаются, поэтому данный вопрос является предметом научного интереса и определяет цель настоящей работы. В ходе работы решалась задача приведения заданных текстов на узбекском языке к нормальной форме, которые на предварительном этапе токенизации были размечены по типам слов и очищены от стоп-слов. Для решения поставленной задачи разработан метод нормализации текстов на узбекском языке на основе алгоритма стемминга. При разработке алгоритма использован гибридный подход на основе совместного применения алгоритмического метода, лексикона лингвистических правил и базы данных нормальных форм слов узбекского языка. Точность предложенного алгоритма зависит от точности работы алгоритма токенизации. При этом, вопрос нахождения корней парных слов, разделенных пробелами здесь не рассматривался, так как эта задача решается, непосредственно, на этапе токенизации. Алгоритм может быть интегрирован в различные автоматизированные системы машинного перевода, извлечения информации, информационного поиска и др.
Ключевые слова:
токенизация, стемминг, лемматизация, простые слова, сложные слова, парные слова, повторяющиеся слова, аффикс, алгоритм, нормальная форма
Abstract: The automatic processing of unstructured texts in natural languages is one of the relevant problems of computer analysis and text synthesis. Within this problem, the author singles out a task of text normalization, which usually suggests such processes as tokenization, stemming, and lemmatization. The existing stemming algorithms for the most part are oriented towards the synthetic languages with inflectional morphemes. The Uzbek language represents an example of agglutinative language, characterized by polysemanticity of affixal and auxiliary morphemes. Although the Uzbek language largely differs from, for example, English language, it is successfully processed by stemming algorithms. There are virtually no examples of effective implementation of stemming algorithms for the Uzbek language; therefore, this questions is the subject of scientific interest and defines the goal of this work. In the course of this research, the author solved the task of bringing the given texts in the Uzbek language to normal form, which on the preliminary stage were tokenized and cleared of stop words. To author developed the method of normalization of texts in the Uzbek language based on the stemming algorithm. The development of stemming algorithm employed hybrid approach with application of algorithmic method, lexicon of linguistic rules and database of the normal word forms of the Uzbek language. The precision of the proposed algorithm depends on the precision of tokenization algorithm. At the same time, the article did not explore the question of finding the roots of paired words separated by spaces, as this task is solved at the stage of tokenization. The algorithm can be integrated into various automated systems for machine translation, information extraction, data retrieval, etc.
Keywords: tokenization, stemming, lemmatization, simple words, difficult words, paired words, repeating words, affix, algorithm, normal form
1. Введение
Наряду с развитием информационных технологий, столь же активно эволюционируют способы представления данных. Однако, неструктурированные тексты на естественных языках по-прежнему остаются наиболее распространенным типом данных и, одновременно, одним из самых сложных для автоматической обработки.
В настоящее время, в мире насчитывается более 7000 живых языков [1], из них немногим более 100 имеют письменность и только 40 считаются самыми распространёнными – на которых говорит примерно две трети населения планеты. Сколь разнообразны естественные языки, столь же разнообразны их семантические и грамматические свойства. По этой причине уже существующие алгоритмы обработки текстов, весьма эффективные для одного языка, часто бывают совершенно неприменимы для текстов на другом языке. Причем речь идёт не только об алгоритмах семантического анализа, считающегося AI-полной задачей [2], но и об алгоритмах решения более узких задач нормализации текста.
Как известно, один и тот же, по сути, поисковый запрос на естественном языке можно составить во множестве вариантов. Поэтому эффективный поисковый механизм должен уметь их все обработать и отождествить между собой, чтобы в итоге выдать релевантный запросу результат.
В этой связи, приведение текста к нормальной (канонической) форме существенно упрощает его дальнейшую обработку в любых автоматизированных системах: поисковые движки, машинные переводчики, системы автореферирования и т.д. Нормализация текста не только значительно улучшает эффективность работы поисковых систем, но и отличается сравнительно низкими требованиями к временным и вычислительным затратам. Не говоря уже о том, что нормализованные тексты позволяют гораздо проще решать задачи их классификации и кластеризации.
Нормализация текста, как правило, подразумевает выполнение ряда базовых процессов, в том числе, токенизацию, стемминг и/или лемматизацию. Токенизация – это процесс разбиения текста до наименьших атомарных единиц (токенов). Стемминг – процесс определения неизменяющейся основы заданного слова (стеммы), которая необязательно совпадает с его морфологическим корнем. Лемматизация – процесс приведения заданного слова к лемме, то есть к его нормальной (словарной) форме.
Стемминг и лемматизация преследуют одну и ту же цель – сокращение флективных форм слов до их нормальной формы. Отличие состоит в том, что алгоритмы стемминга действуют без понимания контекста и разницы между словами, алгоритмы же лемматизации основаны на применении словарей и морфологического анализа.
Хотя лемматизация это более тонкий и точный процесс, соответственно и более ресурсоемкий, тем не менее у алгоритмов стемминга имеются свои преимущества: скорость работы и простота внедрения. Кроме того, во многих случаях низкая аккуратность в нахождении стемм может не иметь критически важного значения.
К числу наиболее популярных реализаций алгоритмов стемминга, разработанных к настоящему времени, относятся стеммеры Д.Б. Ловинс, М. Портера, К. Пэйса и Г. Хаска (алгоритм Ланкастера). Большинство алгоритмических стеммеров в той или иной степени являются производными от них или их модификациями. Кроме того, имеют место алгоритмы стемминга, основанные на статистическом, стохастическом и гибридном подходах, например, Stemka, N-грамм стеммеры, Brute force стеммеры и т.д.
Существующие алгоритмы стемминга в подавляющем числе ориентированы на синтетические языки, то есть те в которых преобладает формообразование с использованием морфем.
Авторы [3] сравнивают алгоритмы стемминга Портера и Ланкастера. Оценка выполнялась на основе ошибок результатов стемминга и визуализации текстовых данных. В качестве исходных данных авторы использовали 10 текстовых документов, которые были выбраны случайным образом из Интернет газет. Полученные авторами результаты показывают, что алгоритм Портера работает эффективнее на 43%, чем алгоритм Ланкастера.
В работе [4] описывается алгоритм нормализации слов на основе классификации окончаний и суффиксов. Общее количество которых составляет 26526 суффиксов и 3565 окончаний. Для всех частей речи построен конечный автомат с учетом морфологических свойств казахского языка. Также авторами разработан алгоритм стемминга без словаря на основе классификации суффиксов и окончаний. Алгоритм протестирован на текстовых корпусах казахского языка.
Авторами работы [5] предложен алгоритм на основе морфологических правил персидского языка, работающий по принципу снизу вверх. Алгоритм состоит из трех этапов: подстроковые теги, соответствие правил, соответствие антиправил. Всего задано 252 правил и 20 антиправил. На первом этапе извлекаются морфологические свойства для всех возможных подстрок. Определяются морфемы и их кластеры, а также основы слов (ядра). На этапе соответствия правил для каждого ядра извлекаются соответствующие правила. Неподходящие к правилам ядра переходят на следующий этап соответствия антиправил. Алгоритм тестировался с помощью текстового корпуса «Hamshahri» и показал корректное извлечение 90,1% основ слов.
В статье [6] разработан новый метод получения основы слов для разных языков. Хотя эксперимент был проведён авторами только для английского и персидского языков. Утверждается, что метод не зависит от морфологических правил языка. В методе используется двуязычный словарь для определения основ слов. Предложенный метод разделён на несколько этапов. На первом этапе проводится кластеризация структурных и семантических сходств слов из словаря. Далее из каждого кластера выбирается слово - кандидат. Эти кандидаты используются для идентификации новых слов. Проведенные эксперименты показывают, что для английского языка метод работает с точностью до 69,52%, а для персидского языка - 70,32%.
Основной недостаток рассмотренных выше алгоритмов стемминга состоит в том, что найденные с их помощью стеммы, далеко не всегда соответствуют морфологическому корню слов. Обычно такие проблемы возникают в тех случаях, когда тип слова заранее неизвестен, либо словоформа образована в соотвествии с несколькими правилами. Таким образом, происходит ситуация, выделенные основы слов сами по себе не имеют смысла.
Узбекский язык является агглютинативным языком, отличающимся полисемантичностью аффиксальных и служебных морфем. Несмотря на то, что узбекский язык имеет множество отличий от английского языка, который также считается агглютинативным, однако он в полной мере допускает применение техники нормализации текстов на основе алгоритмов стемминга.
Целью данной работы является разработка метода нормализации текстов на узбекском языке на основе стемминг алгоритма для обработки слов, структурный тип которых известен заранее.
2. Постановка задачи
Морфологический состав слов узбекского языка включает две основных части: корневая и аффиксальная морфемы. Корень (o‘zak) – это морфема, которая имеет лексическое значение и не имеет аффиксов в своём составе. Аффикс – это морфема, которая может иметь несколько функций. Присоединяясь к корню аффикс образует новое слово или грамматические значение.
Нормальная форма (основа) слов в узбекском языке (negiz) может состоять только из корневой морфемы либо из корневой и аффиксальной морфем одновременно. Основа слов может быть производной и непроизводной. Производная основа состоит из корня и словообразующего аффикса. Например, «gul» (цветок) является непроизводной основой, «guldon» (ваза) – производная основа.
Словообразование может происходить различными способами, в том числе, путем присоединения аффикса к корню «gul+chi» (флорист), путем конкатенации двух простых слов через дефис «baxt-saodat» (счастье), «tez-tez» (часто).
Таким образом, в современном узбекском языке слова по своей структуре бывают: простые, сложные, парные, повторяющиеся (рис. 1).
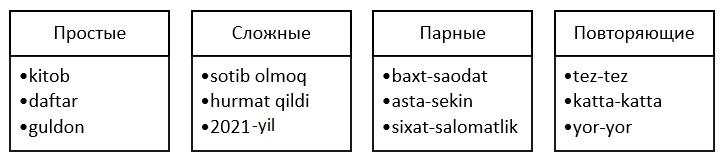
Рис.1. Типы слов по структуре
Отметим, что соответствующее программное средство для определения типов слов узбекского языка, основанное на применении регулярных выражений, было создано нами ранее [7].
Задача состоит в том, чтобы привести к нормальной форме все слова заданного текста, который после предварительного этапа токенизации был размечен по типам слов и подвергнут очистке от стоп-слов.
3. Метод решения
Разработанный алгоритм варьируется в зависимости от типов слов, которым соответствуют следующие обозначения:
ws – простые слова (с производной или непроизводной основой);
wc – сложные слова;
wp– парные слова;
wr – повторяющие слова.
Наибольший интерес представляет задача нормализации слов типа wc и wp, например, соответственно «2021-yillar» и «sixat-salomatlik». Суть алгоритма сводится к тому, что из словоформы удаляются аффиксы, встречающиеся после знака дефис. Если исходное слово не имеет аффиксов, то оно считается стеммой. То есть, «2021-yillar» усекается до «2021-yil» (2021 год), «sixat-salomatlik» усекается до «sixat-salomat» (здравствующий) (рис. 2).
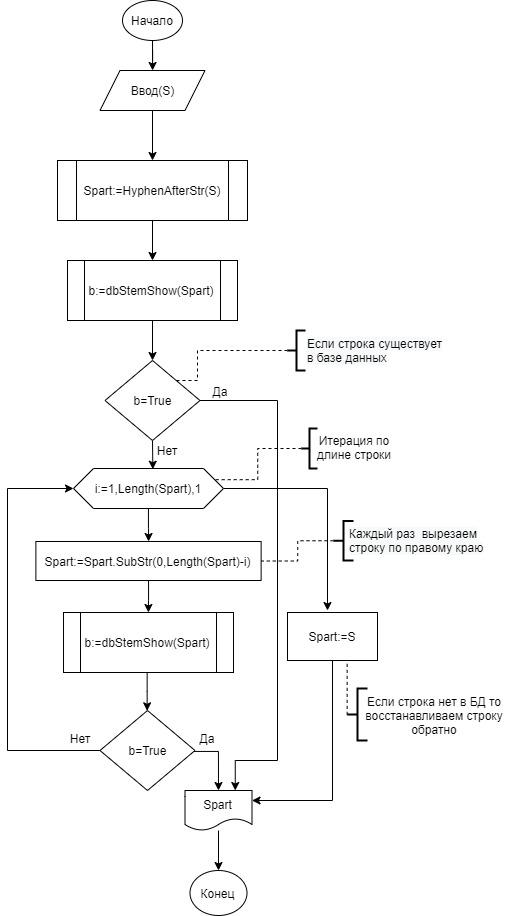
Рис.2. Блок схема алгоритма StemWCWP
Далее опишем переменные и функции алгоритма «StemWCWP» для типов wc и wp :
- «S» – строка;
- «Spart» – строка, содержащая часть строки S;
- «b» – логическая метка;
- «i» – Итерационная переменная;
- «HyphenAfterStr(S)» – пользовательская функция, вырезающая часть строки после знака дефиса;
- «Length(string S)» - стандарная функция возвращения длины строки;
- «dbStemShow(string S)» – пользовательская функция, которая проводит поиск по базе данных;
- «SubStr(firstindex:int, lastindex:int)» – стандарная функция, извлекающая символы, начиная с индекса firstindex до индекса lastindex;
Слова типа wp - «последовательность символов алфавита + знак дефис + последовательность символов алфавита», где слова разлеленные дефисом могут быть идентичными либо первое слово может быть подстрокой второго слова. Во втором случае из второго слова отсекаются любые аффиксы (рис.3).
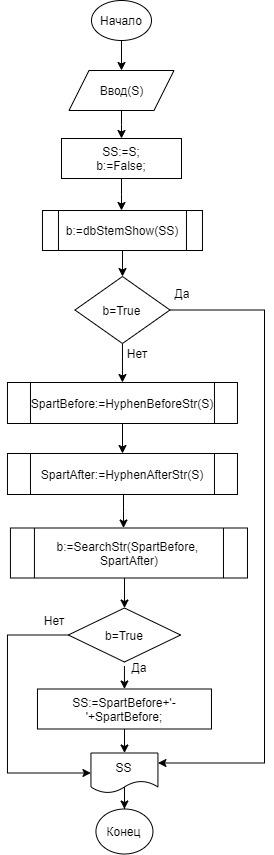
Рис.3. Блок схема алгоритма StemWP
Описание переменных и функций алгоритма StemWP:
- «S» – строка;
- «SS» – строка, содержащая дубликат строки S;
- «b» – логическая метка;
- «SpartBefore» – содержит результат функции HyphenBeforeStr (string S);
- «SpartAfter» – содержит результат функции «HyphenAfterStr(string S)»;
- «HyphenBeforeStr (string S)» – пользовательская функция, вырезающая часть строки до знака дефиса;
- «HyphenAfterStr(string S)» – пользовательская функция, вырезающая часть строки после знака дефиса;
- «SearchStr(string str1, string str2)» – пользовательская функция, проверяющая является ли "str2" частью "str1", если да то возвращает значение true, в противном случае - false.
- «dbStemShow(string S)» – пользовательская функция, которая проводит поиск по базе данных;
Слова типа ws состоят из «последовательность символов алфавита». Иногда в этих словах встречается знак апострофа. Например, «a’lo», «kitob». Чтобы найти основу для такого типа слов удаляется префикс, а не производные аффиксы (рис.4).
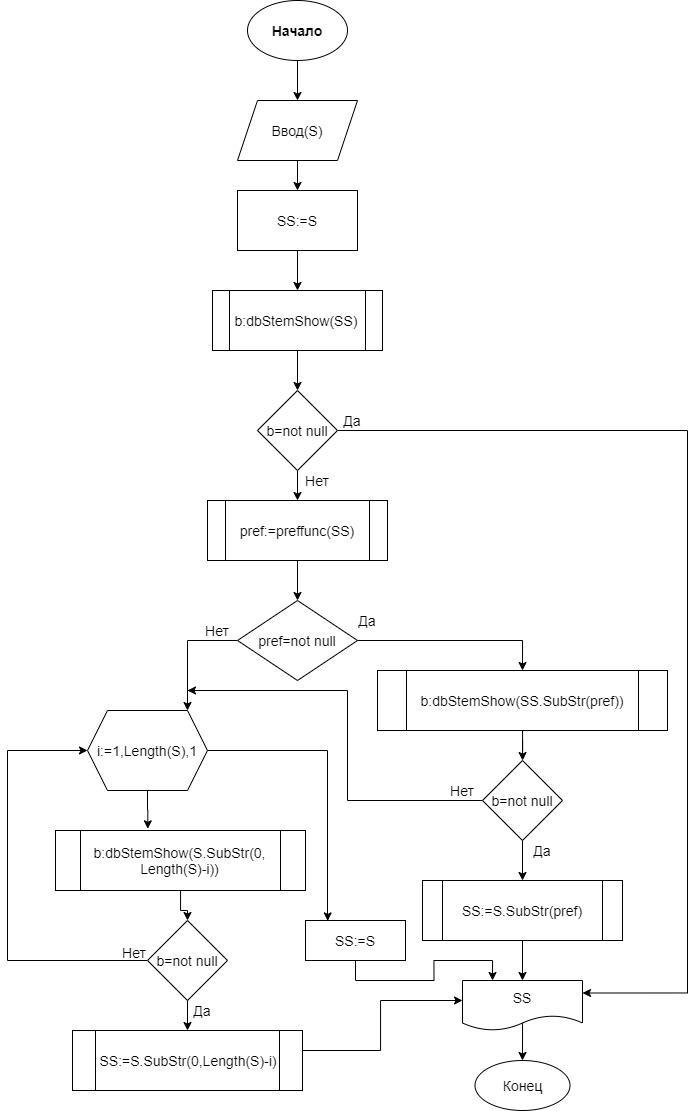
Рис.4. Блок схема алгоритма StemWS
Далее опищем переменные и функции алгоритма StemWS
- «S» – строка;
- «SS» – строка, содержащая дубликат строки S;
- «b» – логическая метка;
- «i» – итерационная переменная;
- «pref» – строка для префиксов;
- «Length (string S)» – стандарная функция, возвращающая длину строки;
- «dbStemShow(string S)» – пользовательская функция, которая проводит поиск по базе данных;
- «preffunc(string S)» – пользовательская функция, извлекающая префиксы из строковой переменной;
- «SubStr(firstindex:int, lastindex:int)» – стандарная функция, извлекающая символы, начиная с индекса firstindex до индекса lastindex;
Обсуждение результатов. Для тестирования алгоритма использовался текстовые корпуса по жанрам: сказки, законодательные документы, узбекские пословицы и религиозные произведения табл.1.
Таблица №1
|
№
|
Выбранные текстовые корпуса по жанрам
|
Число слов
|
Правильные основы
|
|
1.
|
Сказки
|
1246
|
96 %
|
|
2.
|
Законодательные документы
|
1290
|
92,5 %
|
|
3.
|
Религиозные произведения
|
1285
|
91,3 %
|
|
4.
|
Узбекские пословицы
|
1200
|
94%
|
Заключение
Таким образом, разработан метод нормализации текстов на узбекском языке на основе алгоритма стемминга. При разработке алгоритма использовался гибридный подход на основе совместного применения алгоритмического метода, лексикона лингвистических правил и базы данных нормальных форм слов узбекского языка. Точность предложенного алгоритма зависит от точности работы алгоритма токенизации. При этом, вопрос нахождения корней парных слов, разделенных пробелами здесь не рассматривался, так как эта задача решается, непосредственно, на этапе токенизации. Алгоритм может быть интегрирован в различные автоматизированные системы машинного перевода, извлечения информации, информационного поиска и др.
Библиография
1. Over 7000 languages are spoken in the world today, but not many are represented online // Consumers International. – URL: https://bit.ly/2ToxLQR.
2. Yampolskiy R.V. AI-Complete, AI-Hard, or AI-Easy: Classification of Problems in Artificial Intelligence // Midwest Artificial Intelligence and Cognitive Science Conference. – Cincinnati, 2012. – P. 1-8. – URL: https://bit.ly/3vDqhI1.
3. Razmi N.A. et al. Visualizing stemming techniques on online news articles text analytics // Bulletin of Electrical Engineering and Informatics. – 2021. – Vol. 10. – №1. – P. 365-373.
4. Rakhimova D.R., Turganbaeva A.O. Normalization of kazakh language words // Sci. Tech. J. Inf. Technol. Mech. Opt. – 2020. – Vol. 20, №4. – P. 545-551.
5. Sharifloo A., Shamsfard M. A Bottom Up approach to Persian Stemming // Int'l Joint Conf. on Natural Language Processing : Vol. 2. – Hyderabad, 2008. – P. 583-588.
6. Hassan Diyanati M. et al. Words Stemming Based on Structural and Semantic Similarity // Comput. Eng. Appl. – 2014. – Vol. 3, №2. – P. 89–99.
7. Bakaev I.I. Linguistic features tokenization of text corpora of the Uzbek language // Bulletin of TUIT: Management and Communication Technologies. – 2021. Vol. 4. – P. 1-8.
References
1. Over 7000 languages are spoken in the world today, but not many are represented online // Consumers International. – URL: https://bit.ly/2ToxLQR.
2. Yampolskiy R.V. AI-Complete, AI-Hard, or AI-Easy: Classification of Problems in Artificial Intelligence // Midwest Artificial Intelligence and Cognitive Science Conference. – Cincinnati, 2012. – P. 1-8. – URL: https://bit.ly/3vDqhI1.
3. Razmi N.A. et al. Visualizing stemming techniques on online news articles text analytics // Bulletin of Electrical Engineering and Informatics. – 2021. – Vol. 10. – №1. – P. 365-373.
4. Rakhimova D.R., Turganbaeva A.O. Normalization of kazakh language words // Sci. Tech. J. Inf. Technol. Mech. Opt. – 2020. – Vol. 20, №4. – P. 545-551.
5. Sharifloo A., Shamsfard M. A Bottom Up approach to Persian Stemming // Int'l Joint Conf. on Natural Language Processing : Vol. 2. – Hyderabad, 2008. – P. 583-588.
6. Hassan Diyanati M. et al. Words Stemming Based on Structural and Semantic Similarity // Comput. Eng. Appl. – 2014. – Vol. 3, №2. – P. 89–99.
7. Bakaev I.I. Linguistic features tokenization of text corpora of the Uzbek language // Bulletin of TUIT: Management and Communication Technologies. – 2021. Vol. 4. – P. 1-8.
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
Представленная на рецензирование статья посвящена вопросам совершенствования алгоритмов обработки текстов на различных естественных языках путем нормализации текста и упрощения его дальнейшей обработки в различных автоматизированных информационных системах.
Методология исследования базируется на изучении наиболее популярных алгоритмов стемминга, разработанных к настоящему времени (стеммеры Д.Б. Ловинс, М. Портера, К. Пэйса и Г. Хаска), их применении для анализа текстов на английском, персидском, казахском и др. языках, построении блок-схем алгоритмов нормализации простых, сложных, парных и повторяющихся слов узбекского языка.
Актуальность темы исследования автор связывает с тем, что эффективные алгоритмы обработки текстов для одного языка часто бывают неприменимы для текстов на другом языке, поскольку существующие алгоритмы стемминга в основном ориентированы на синтетические языки, в которых преобладает формообразование с использованием морфем, а узбекский язык является агглютинативным языком, отличающимся полисемантичностью аффиксальных и служебных морфем. Автор статьи исходит из того, что узбекский язык имеет множество отличий от английского языка, который также считается агглютинативным, однако он в полной мере допускает применение техники нормализации текстов на основе алгоритмов стемминга - определения неизменяющейся основы заданного слова (стеммы), которая необязательно совпадает с его морфологическим корнем.
Научная новизна представленного исследования, по мнению рецензента, заключается в разработке метода нормализации текстов на узбекском языке на основе стемминг алгоритма для обработки слов, структурный тип которых известен заранее.
В статье структурно выделены следующие разделы: 1. Введение, 2. Постановка задачи, 3. Метод решения, Обсуждение результатов, Заключение, Библиография.
Во введении говорится о том, что только 40 современных живых языков считаются самыми распространёнными, на которых говорит примерно две трети населения планеты, разнообразие естественных языков, их семантических и грамматических свойств затрудняет применение существующих алгоритмов обработки текстов, а эффективный поисковый механизм в условиях информатизации должен быть приспособлен для обработки текста на различных языках. Здесь же приведен понятийный аппарат, определения терминов «нормализация текста», «токенизация», «стемминг», «лемматизация», сделан краткий обзор наиболее известных алгоритмов стемминга, названы их недостатки, сформулирована цель исследования. В следующем разделе статьи приведены типы слов по структуре в узбекском языке, отражена постановка задачи. В разделе «Метод решения» на отдельных рисунках приведены блок-схемы предлагаемых алгоритмов для обработки разных типов слов. В ходе обсуждения полученных результатов предпринята попытка описания тестирования алгоритма с использованием различных жанров. Итоги исследования сформулированы в Заключении.
В целом содержание и стиль изложения материала соответствует сложившейся при оформлении результатов научных исследований практике публикаций.
В тоже время следует отметить недоработки авторов рецензируемой статьи.
Во-первых, раздел «Обсуждение результатов», состоящий всего из одного предложения и одной таблицы, представляется целесообразным изложить более детально, пояснить приведенные в таблице 1 данные, интерпретировать полученные результаты.
Во вторых, таблица 1 не озаглавлена, не имеет названия.
Рецензируемое исследование выполнено на актуальную тему, соответствует тематике журнала «Кибернетика и программирование», содержит элементы приращения научного знания, ориентировано на разработку метода нормализации текстов на узбекском языке на основе алгоритма стемминга, который может быть интегрирован в различные автоматизированные системы машинного перевода, извлечения информации и информационного поиска, материал статьи может вызвать интерес как узкопрофильных специалистов, так и широкого круга читательской аудитории – все это свидетельствует о возможности опубликования рецензируемой статьи после устранения отмеченных выше недоработок.
|











