|
DOI: 10.25136/2644-5522.2020.1.32143
Дата направления статьи в редакцию:
08-02-2020
Дата публикации:
03-07-2020
Аннотация:
Предметом исследования является возможность применения XPath-подобных микроязыков программирования в системах порождения программ класса PGEN++ для выделения и достраивания XML-моделей, описывающих план решения исходной задачи, по которому генерируется решающая программа. Предполагается построение таких моделей по описанию задачи на естественном языке, таким образом, речь идет об элементах технологий искусственного интеллекта. XPath-подобный язык работает в слое регулярно-логических выражений (выделяющем элементы первичного XML-документа), выполняя первичную обработку данных, полученных в слое грамматического разбора исходного текста. Кроме того, XPath-подобные элементы используются для вывода финальных XML-моделей. Используются стандартные библиотеки грамматического разбора текстов на естественном языке. Используются нестандартные расширения языка запросов XPath. Впервые предложена идея расширения языка запросов XPath до уровня алгоритмического языка, путем ввода минимально необходимого количества синтаксических элементов. Также предложено применение синтаксических элементов c XPath-подобной структурой в качестве как порождающих так и контролирующих слабых ограничений процесса прямого логического вывода финальных смысловых XML-моделей.
Ключевые слова:
искусственный интеллект, порождение программ, алгоритмический XPath, слабые ограничения, достраивание модели, алгоритмическая полнота, обработка естественного языка, смысловая модель, прямой логический вывод, грамматический разбор
Abstract: The subject of the research is the possibility of using XPath-like micro-languages of programming in the generation systems of programs of the PGEN ++ class for the selection and completion of XML-models describing the plan for solving the original problem, according to which the solver program is generated. It is supposed to build such models according to the description of the problem in natural language, thus, we are talking about elements of artificial intelligence technologies. XPath-like language works in the layer of regular-logical expressions (highlighting elements of the primary XML document), performing primary processing of the data obtained in the layer of grammatical parsing of the source text. In addition, XPath-like elements are used to render the final XML models. The standard natural language parsing libraries are used. Non-standard XPath query language extensions are used. For the first time, the idea of expanding the XPath query language to the level of an algorithmic language by introducing the minimum required number of syntactic elements is proposed. It is also proposed to use syntactic elements with an XPath-like structure as both generating and controlling weak constraints of the process of direct inference of final semantic XML models.
Keywords: artifical intelligence, program generation, algorithmic XPath, weak restrictions, model completion, algorithmic completness, natural-language processing, sense model, direct inference, link-grammar parsing
Одной из важных задач в области искусственного интеллекта является, в частности, задача генерации решающей некоторую проблему программы по естественно-языковому описанию этой проблемы. Данная задача, которую при современном уровне развития технологий искусственного интеллекта вряд ли возможно решить универсально и в полном объеме, тем не менее может эффективно решаться системами порождения программ в целом ряде достаточно проработанных и формализованных областей (математические задачи, задачи проектирования стандартизованных технических объектов, различные типовые задачи программирования [в частности, генерация интерфейсов, генерация Web-контента, генерация подсистем для работы с базами данных и многие другие шаблонно решаемые задачи]). Поэтому, данная задача интересна не только теоретически, но и практически, и, несомненно, актуальна.
Существует два основных направления решения поставленной задачи: а) прямая трансформация постановочного текста на естественном языке в текст программы [1, 2] и б) многостадийная трансформация естественно-языковой постановки в программу (обязательным компонентом такой трансформации является выработка некоторой смысловой модели (например, плана решения задачи) [3, 4, 5]).
Первое направление может использовать продукционные правила в сочетании с нейросетями, определяющими сравнительные вероятности применения того или иного правила (как это сделано в работе [1]), или прибегать к помощи технологии Statistical Machine Translation (SMT), которая определяет статистически лучшие варианты прямой трансляции отдельных фрагментов входной постановки в фрагменты выходной постановки, объединяет их и проверяет результат по некоторой языковой модели [2]. При всей интересности данного направления нельзя не признать, что оно более перспективно для решения достаточно локальных задач, таких как автокомментирование программного кода или машинный перевод, выполняемый по отдельным предложениям. Задача же генерации программы может требовать комплексного анализа смысла исходного текста в целом.
Поэтому, более продуктивным представляется второе направление. В его рамках возможны различные подходы к построению смысловой модели. Например, в системе IPGS [3] используются многоленточные машины Тьюринга в сочетании с элементами теории формальных грамматик. Данный подход вряд ли прост в применении, более перспективным представляется подход, при котором используются (в той или иной форме) хорошо известные схемы определения грамматических связей между отдельными словами [6], даже на основании первичного анализа которых уже можно делать некоторые выводы о содержании поставленной задачи. Такой подход успешно представлен, например, в работах [4, 5]. Однако нельзя не отметить общий недостаток этих работ – крайнюю простоту получаемой смысловой модели и механизма, реализующего генерацию кода (используются специальные таблицы трансляции). Вызывает определенное сомнение пригодность подобной схемы для существенно более сложных случаев (нежели разобранные в упомянутых работах), особенно требующих дополнения выделенной смысловой модели (которая может быть представлена в крайне неполном, возможно, чисто декларативном виде) до полного плана решения задачи.
Представляется целесообразным построение смысловой модели за два этапа. На первом этапе необходимо провести лексико-синтаксический разбор исходного текста на естественном языке с разбивкой его на предложения, с выявлением отдельных элементов предложений и анализом грамматических связей между этими элементами. В результате получаем первичную фактологическую модель текста, включающую набор высказываний, каждое из которых может быть описано объектом некоторого класса заданной предметной области (схожий подход применен в [5]). Каждый класс представляет либо некоторую сущность, либо действие, либо отношение, а поля соответствующего объекта такого класса содержит, соответственно, атрибуты сущности, объект/субъект действия, параметры отношения.
На втором этапе построения смысловой модели выявленный набор первичных объектов анализируется (уже на уровне отношений между различными объектами) и достраивается до полной модели, содержащей уже все необходимую для решения поставленной задачи информацию. Данный процесс достаточно нетривиален алгоритмически, поэтому его целесообразно решать в некоторой формально-логической постановке. Здесь, вообще говоря, возможны два основных подхода – прямой и обратный логический вывод. Обратный вывод целесообразно использовать в случаях, когда четко ясна структура целевого утверждения. В нашем случае это, фактически, означает, что должны быть заранее ясны структура и состав конечной смысловой модели. На практике это не так. Поэтому более целесообразно применение прямого логического вывода, для которого задается не целевое утверждение, а некоторые наборы ограничений процесса построения и наборы тестов, через которые должна успешно проходить программа, сгенерированная по очередному (формально корректному) варианту плана решения задачи.
Заметив, что эффективное программирование прямого логического вывода является достаточно нетривиальной задачей даже для программиста, а пользователями системы порождения программ преимущественно являются непрограммирующие специалисты по знаниям в определенных предметных областях, целесообразно максимально упростить как форму представления смысловой модели, так и правила ее элементарного анализа и логического достраивания.
Такой формой может быть XML-документ, набор тэгов которого способен содержать описания не только объектов, входящих в план решения задачи, но и отношений между ними. В связи с этим логично выбрать в качестве базового средства анализа и достраивания документа какой-либо из стандартных формальных языков обработки XML-документов. В частности, достаточно интересным представляется выбор языка запросов XPath, причем существенный (не только теоретический, но и практический) интерес представляют его модификации, позволяющие применить основанный на XPath синтаксис для конструирования и описания небольших простых алгоритмов, носящих вспомогательный характер.
Итак, целью данной работы является повышение функциональности схем порождения программ по естественно-языковой постановке задачи. Для достижения данной цели поставим следующие задачи: а) предложить (на базе XPath) простые языковые средства обработки результатов грамматического разбора при построении первичной смысловой модели; б) предложить адекватные языковые средства (также на базе XPath) для анализа первичной смысловой модели и ее достраивания до полной модели; в) реализовать предложенные схемы и подходы в системе порождения программ PGEN++ [7, 8], которая обеспечивает успешную генерацию программ в четко формализованных предметных областях, для которых возможна разработка адекватных порождающих классов.
Применение XPath-подобного языка при построении первичной смысловой модели
Как уже было отмечено выше, построение первичной смысловой модели в системе PGEN++ включает лексико-синтаксический разбор исходного текста с разбивкой его на предложения, с выявлением отдельных элементов предложений и анализом грамматических связей между этими элементами. Данные операции выполняются специальными классами (из описания предметной области), нагруженными распознающими методами, каждый из которых содержит шаблон разбора, представляющий собой группу регулярно-логических выражений в сочетании с набором указаний по извлечению информации из результатов разбора и помещению их в поля объектов, формирующих первичную XML-модель.
Регулярно-логические выражения (в базовой версии достаточно подробно описаны в работе [8]) представляют собой расширение стандартных регулярных выражений [9], включающее возможность исполнения цепочек специальных микропредикатов, выполняющих вспомогательную обработку распознанных фрагментов – проверку по простейшим CSV-таблицам, модификации таких таблиц, работу с нейронными сетями прямого распространения, а также различные сложные алгоритмические проверки, в число которых входит грамматический анализ фрагментов предложений на естественном языке (на нижнем уровне таких проверок используется библиотека Link Grammar 5.3.0 [10]). Выходная информация библиотеки Link Grammar (набор выявленных грамматических связей между словами) представляется (для обеспечения единообразного формата данных в системе) в виде виртуального XML-документа, в связи с чем, в набор микропредикатов регулярно-логических выражений потребовалось ввести специальные средства для работы с такими XML-документами. В соответствии с общей концепцией данной работы было принято решение использовать в качестве таких средств XPath-подобный запросо-алгоритмический язык, дополнив стандартный XPath несколькими конструкциями.
В-целом, стандартный XPath уже имеет доступные для чтения переменные (записываемые в формате $ИМЯ) и обладает элементарными возможностями последовательного и ветвящегося исполнения серий логических функций (при условии, что используется стандартная концепция сокращенного исполнения логических выражений). В самом деле, XPath-выражение вида
A(…) and B(…) and C(…)
может трактоваться как линейный фрагмент программы, подразумевающий последовательный вызов функций A(…), B(…) и C(…), при условии, что данные функции возвращают истинное логическое значение. Аналогично, выражение
D(…) and E(…) or F(…)
может рассматриваться как условный оператор, который исполняет либо функцию E(…), если результат D(…) истинен, либо функцию F(…), если результат D(…) ложен.
Таким образом, чтобы покрыть базовые потребности программирования, необходимо ввести возможность программного определения новых функций XPath (если при этом разрешить рекурсию, то с помощью функций можно реализовать еще и циклы) и ввести, как минимум, одну новую стандартную функцию (результат исполнения которой всегда истинен)
«set» «(» «$» имя_переменной «,» выражение «)»
которая позволит присваивать значение выражения переменной.
Предлагается следующий синтаксис программно определяемой функции:
функция = «*» имя_функции «(» [список_параметров] «)» XPath-выражение «.»
имя_функции = идентификатор
список_параметров = параметр {«,» параметр}
параметр = параметр_по_ссылке | параметр_по_значению
параметр_по_ссылке = «&» «$» идентификатор
параметр_по_значению = параметр_указатель | параметр_не_указатель
параметр_указатель = «$» «#» {«#»} [идентификатор]
параметр_не_указатель = «$» идентификатор
где XPath-выражение является телом функции, причем его значение определяет результат исполнения функции. Параметры могут передаваться как по ссылке, так и по значению, их имена всегда префиксуются символом «$». Имена числовых, строковых и логических параметров могут быть произвольными идентификаторами, имена параметров-указателей на отдельные фрагменты XML-документа дополнительно префиксуются одним или несколькими символами «#» (при этом для получения элемента по такому указателю в теле функции используется его имя с префиксами «#», но без начального знака «$»). Вызов программно определяемой функции оформляется таким же образом, как и вызов любой стандартной XPath-функции.
Приведем два примера программно определяемой функции.
Рекурсивная функция loop($I, $max, $body) исполняет в цикле XPath-выражение, записанное в строковом параметре $body, цикл выполняется по переменной-счетчику $I, от ее переданного начального значения до значения $max включительно.
* loop($I,$max,$body) ($I <= $max and set($I, $I+1) and eval($body) and loop($I,$max,$body)) or true().
Здесь фигурирует еще одна новая стандартная функция:
eval «(» строковое_выражение «)»
которая исполняет переданное в нее строковое выражение, интерпретируя его как XPath-выражение. Вычисленное значение этого выражения является результатом функции eval.
Рекурсивная функция depth(&$OUT1) помещает в свой параметр $OUT1 значение максимальной глубины поддерева XML-тэгов, начиная с точки документа, в которой была вызвана данная функция:
* depth(&$OUT1) set($OUT1,0) and (self::*[set($OUT1,1) and *[depth($OUT0) and set($OUT1,max($OUT0+1,$OUT1))]] or true()).
Следует заметить, что, для полноценности, такому микроязыку программирования необходима также поддержка динамических структур данных (как минимум их создания и удаления). Поэтому целесообразен ввод еще трех новых функций:
«create» «(» XPath-запрос «)»
которая создает новые элементы XML-документа путем применения XPath-запроса в конструирующем смысле [11],
«delete» «(» XPath-запрос «)»
которая удаляет элементы XML-документа, которые возвращает XPath-запрос,
«transaction» «(» выражение «)»
которая выполняет выражение (содержащее create/delete-утверждения) в едином, атомарно принимаемом или отменяемом блоке. Если выражение истинно, то транзакция принимается, иначе – отменяется.
В качестве примера приведем набор функций, которые позволяют создать в XML-документе список путем конкатенации двух уже существующих списков (список представляет собой цепочку вложенных тэгов list с атрибутами data, в которых хранятся значения соответствующих элементов списка):
*concat_list($#,$##) add_list(#/self::*) and add_list(##/self::*).
*add_list($#) count(list) = 0 and copy_list(#/self::*) or list[add_list(#/self::*)] or true().
*copy_list($#) count(#/list) = 0 or create(list[@data = #/list/@data]) and (list[copy_list(#/list)] or true()).
Вызов функции конкатенации при этом может иметь вид:
transaction(concat_list(/a/b,/a/c))
при этом вложенные цепочки тэгов list (с атрибутами data) из тэгов, определяемых результатами запросов /a/b и a/c, будут объединены в общую вложенную цепочку и помещены в точку документа, из которой осуществлялся вызов конкатенации.
И, наконец, дадим реальный пример функции, которая используется в регулярно-логических выражениях в системе PGEN++ в качестве одного из элементов интерфейса со слоем грамматического разбора:
* action(&$VERB,&$OBJ): /*/Link[Name/text()="MVv" and set($VERB,Left/Value/text()) and set($OBJ,Right/Value/text()) or
Name/text()="MVIv" and set($OBJ,Left/Value/text()) and set($VERB,Right/Value/text())].
Данная функция применяется к результатам грамматического разбора некоторого фрагмента текста, выделенного регулярно-логическим выражением, находит в нем глагол, применяемый по отношению к некоторому объекту, и помещает глагол в параметр $VERB, а объект – в $OBJ, в этом случае функция возвращает истину. Если же предложение не содержит указанной грамматической конструкции, функция возвращает ложь. В настоящее время разработано несколько подобных функций, облегчающих взаимодействие микропредикатов регулярно-логических выражений со слоем грамматического разбора в целях выявления смысла исходной естественно-языковой постановки задачи.
Тезис об алгоритмической полноте разработанного микроязыка по Тьюрингу. Разработанный XPath-подобный язык алгоритмически полон по Тьюрингу.
Неформальное доказательство. Сравним описательно-алгоритмические возможности разработанного языка и языка GNU Prolog. Оба языка схожим образом позволяют описать линейные цепочки операторов (вызовов функций или предикатов), ветвящиеся цепочки операторов, циклы (с помощью рекурсии), функции (предикаты Prolog/функции разработанного языка). В обоих языках возможно применение переменных, работа с динамическими данными сложной структуры (базы предикатов и сложные термы в Prolog с одной стороны, и тэги/блоки тэгов в разработанном языке с другой стороны). Соответствие установлено. Поскольку GNU Prolog является алгоритмически полным по Тьюрингу (на нем можно написать машину Тьюринга, реализующую любой разрешимый по Тьюрингу алгоритм), разработанный язык также является алгоритмически полным по Тьюрингу.
Следствие. Разработанный XPath-подобный язык способен реализовать произвольный разрешимый по Тьюрингу алгоритм обработки данных грамматического разбора.
Применение XPath-подобных элементов в качестве слабых ограничений процесса прямого логического вывода финальной смысловой модели
Как уже упоминалось выше, генерация финальной смысловой модели (полного плана решения задачи) организуется по схеме прямого логического вывода. При этом используется набор слабых ограничений – некоторых правил, работающих в проверочном и, возможно, в конструирующем режиме. В проверочном режиме правила определяют соответствие текущего варианта модели некоторым критериям, а в конструирующем – дополняют (если это возможно) модель таким образом, чтобы данные критерии выполнялись хотя бы локально.
На каждом этапе вывода к текущему варианту модели применяются все правила в проверочном режиме. Для каждого правила определяется, нарушено ли оно, и каким является прогноз по исправлению несоответствия. Если хотя бы по одному правилу прогноз строго отрицательный, текущий вариант модели отвергается и выполняется откат. Если по всем правилам результат строго положительный, то полученный вариант является возможным решением и проверяется на глобальное соответствие (выявляется с помощью набора тестов, через которые должна успешно проходить программа, сгенерированная по текущему варианту плана решения задачи). Если же по некоторым правилам прогноз исправления скорее положительный, то такие M правил поочередно применяются в конструирующем режиме с ветвлением вывода, соответственно, на M новых вариантов модели, к каждому из которых применяется вся вышеописанная схема дальнейшего вывода с проверкой.
Полное рассмотрение данного механизма, примененного в системе PGEN++, выходит за рамки данной работы, отметим лишь, что он является распараллеленным, контролируется по времени вывода (при превышении которого осуществляется сброс процесса с реинициализацией), реализуется вероятностной (марковской) моделью, веса которой определяются обобщенно-регрессионной нейронной сетью, дополнительно анализирующей структуру и содержание грамматически разобранной исходной постановки. В связи с этим, правила имеют веса (относительные вероятности применения), которые будут упоминаться в дальнейшем изложении.
Заметим, что финальный вариант смысловой модели описывается уже не просто массивом распознанных объектов, как в первичном варианте, а ориентированным сетевым графом, узлами которого являются объекты, а связи отражают отношения между объектами в плане решения задачи. Тем не менее, данная сеть также представляет собой XML-документ (связи между объектами устанавливаются с помощью ссылок на уникальные идентификаторы объектов или связей объектов), соответственно, все проверки и трансформации выполняются также над документом.
Определим 4 вида правил:
1. Конструирующее правило единственности. Имеет синтаксис:
[знак] [вес] XPath-выражение «.»
знак = инверсия | «+»
инверсия = «-»
вес = «{» вещественное_число «}»
Данное правило в проверочном режиме определяет, возвращает ли указанное XPath-выражение единственный элемент, а в конструирующем режиме достраивает документ, воспринимая XPath-выражение как конструирующее. Знак, в этом и последующих правилах, управляет смыслом, в котором данное правило воспринимается в проверочном режиме: если указана инверсия, то результат проверки R преобразуется в результат U по следующим правилам:
«соответствие» => «нарушение правила с отрицательным прогнозом»,
«нарушение правила (с любым прогнозом)» => «соответствие».
2. Проверочное правило следования. Имеет синтаксис:
[знак] [вес] «[» XPath-выражение-1 «]» «>>» «[»XPath-выражение-2 «]» «.»
Данное правило вычисляет наборы объектов J1 и J2 текущей модели, представленной XML-документом, соответствующих узлам документа, выделяемым запросами XPath-выражение-1 и XPath-выражение-2. Правило возвращает соответствие, если в графе-модели из любой вершины, входящей в J1, существует путь в какую-либо вершину, входящую в J2.
3. Проверочное правило количественного отношения. Имеет синтаксис:
[знак] [вес] «[» XPath-выражение-1 «]» отношение «[»XPath-выражение-2 «]» «.»
отношение = «<» | «>» | «<=» | «>=» | «=» | «!=»
Данное правило вычисляет XPath-выражение-1 и XPath-выражение-2 с результатами K1 и K2 соответственно. Правило возвращает соответствие, если K1 находится в указанном отношении с K2, смысл отношения зависит от типов K1 и K2.
4. Конструирующее правило восполнения.
[знак] [вес] «[» XPath-выражение-1 «]» оператор «[»XPath-выражение-2 «]» «.»
оператор = «=>» | «=>>»
Здесь одно и только одно (любое) из указанных XPath-выражений (A) должно иметь ссылки на некоторые элементы другого выражения (B), обозначаемые одним или несколькими знаками «#». В проверочном режиме правило вычисляет выражение B, после чего определяет: а) в случае оператора «=>» – существует ли набор узлов, соответствующий выражению A; б) в случае оператора «=>>» – существует ли набор узлов, соответствующий выражению A, причем узлы, соответствующие XPath-выражению-1 должны присутствовать в документе ближе к его началу (к истоку сетевой модели), чем узлы, соответствующие XPath-выражению-2. Результатом проверки является соответствие (существует) или нарушение с положительным прогнозом исправления (не существует). В конструирующем режиме правило достраивает документ, воспринимая XPath-выражение A как конструирующее. Это правило является основным, определяющим, фактически, условное достраивание. При этом наличие оператора «=>>» позволяет выполнять достраивание, явно руководствуясь последовательностью «изложения» XML-документа модели, которая в системе PGEN++ совпадает с последовательностью соответствующих элементов в исходной постановке задачи, в ряде случаев отражающей порядок применения каких-либо операций, характерных для процесса решения задачи.
Приведем примеры нескольких правил для учебной предметной области – простой обработки векторных данных (поиск минимума, максимума, среднего):
[/OBJS/clsSimpleProgram] >> [/OBJS/clsSimpleBlock]. – правило предшествования объекта «старт программы» всем прочим объектам-блокам программы;
[/OBJS/clsSimpleProgram] = [1]. – правило единственности объекта «старт программы»;
[/OBJS/clsSimpleVector[@ID = #/@IVar and (@Size != "")]/O[@ID="Handle"]/Link[@Code = ##/@Ref]] => [/OBJS/clsSimpleBlock[@IVar != ""]/I[@ID="Arg"]]. – правило дополнения модели объектом-блоком, декларирующим наличие обрабатываемого вектора, в случае, если существует обрабатывающий вектор объект-блок, причем эти блоки должны быть связаны по определенным контактам;
[/OBJS/clsSimpleBlock[@ID != ""]/O[@ID="Next"]] =>> [/OBJS/clsSimpleBlock[@ID != "" and @ID != #/@ID]/I[@ID="Prev"]/Link[@Code = ##/@Ref]]. – общее правило, декларирующее, что связи объектов-блоков должны существовать (между определенными контактами) и не должны противоречить порядку упоминания соответствующих текстовых фрагментов в исходной постановке задачи.
Апробация
В настоящее время изложенные выше идеи в полной мере реализованы в системе порождения программ PGEN++. Механизм вывода смысловых моделей реализован на языках Free Pascal и GNU Prolog, распараллелен, является отчуждаемым от интерфейсно-графической оболочки PGEN++, и работает в операционных системах Windows и Linux на многоядерных вычислителях.
На базе данного механизма реализован (в двух версиях: а) на основе чистых регулярно-логических выражений и обратного логического вывода, и б) на основе прямого логического вывода с применением слоя грамматического разбора и системы слабых ограничений) естественно-языковой интерфейс для задач порождения программ для простой обработки векторных данных. Ввиду большого объема тексты макросов порождающих классов и наборы XPath-функций и правил – слабых ограничений в данной работе не приводятся (выше содержатся некоторые фрагменты таких наборов).
В качестве примера приведем лишь естественно-языковую постановку простой исходной задачи, фрагмент полученной объектной диаграммы (являющейся визуальным представлением выведенной XML-модели, см. рис. 1) в системе PGEN++, соответствующей выведенному плану решения задачи, и сгенерированную программу (см. рис. 2).
Постановка задачи: «Составить программу. Ввести скаляр max. Ввести скаляр min. Введем вектор V из 10 элементов. Зададим вектор V с клавиатуры. Найдем минимум вектора V и поместим результат в скаляр min. Найдем также максимум вектора V и поместим результат в скаляр max. Вывести скаляр min на экран. Вывести скаляр max на экран. Вывести вектор V на экран. А среднее арифметическое считать не будем.».
Отметим, что данная постановка может быть сокращена, например, если убрать первые три предложения, то система PGEN++ за счет механизма дополнения смысловой модели, восполнит ее в процессе вывода. Аналогично, может быть убрано последнее предложение, не несущее в данном случае смысловой нагрузки и введенное лишь в качестве "лингвистического шума".
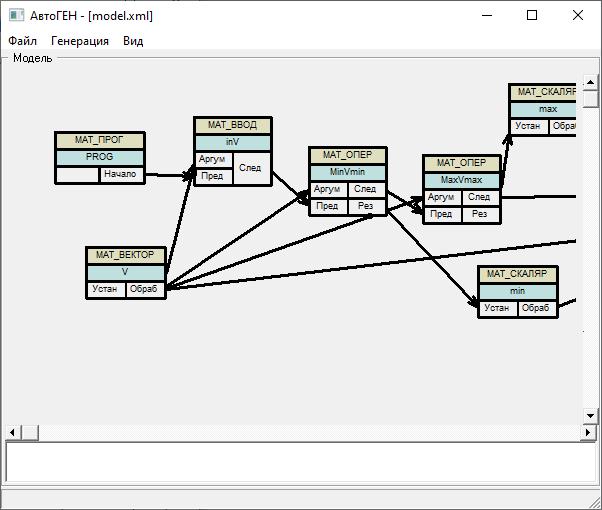
Рис. 1. Фрагмент полученной XML-модели в визуальной форме
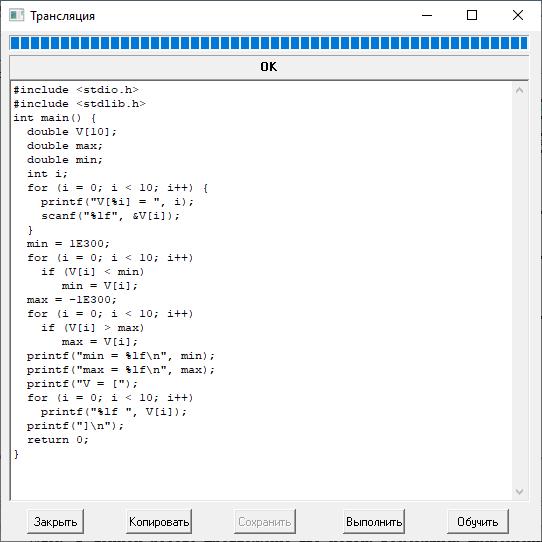
Рис. 2. Окно со сгенерированной системой программой
Приведенные результаты свидетельствуют о достоверности изложенных в данной работе подходов, о возможности их успешного применения (для выделения и восполнения смысловых моделей - планов решения исходной задачи) и об их корректной реализации в системе PGEN++.
Заключение
Итак, в данной работе предложены два новых возможных применения XPath-подобных языков в задачах построения смысловых моделей по исходным текстам на естественном языке (в системах порождения программ):
а) сформулированы основные принципы записи алгоритмических конструкций в XPath-подобном языке, предложено его применение в качестве микроязыка обработки результатов грамматического разбора в системах порождения программ, показана алгоритмическая полнота (по Тьюрингу) такого микроязыка;
б) предложены синтаксис и семантика XPath-подобных слабых ограничений, управляющих процессом достраивания (прямого логического вывода) финальных смысловых XML-моделей исходной задачи;
в) предложенные подходы успешно применены в системе порождения программ PGEN++ (рассмотрен пример тестовой задачи о простой обработке векторных данных).
Библиография
1. Yin P., Neubig G. A syntactic neural model for general-purpose code generation. In: ACL (1), pp. 440–450 (2017).
2. Oda Y., Fudaba H., Neubig G. et al. Learning to Generate Pseudo-code from Source Code using Statistical Machine Translation // 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2015. pp. 574-584.
3. Зубков В. П., Назаретский С. П. IPGS — интеллектуальная система ав-томатизированного программирования// Инф. среда вуза: Сб. ст. Иваново: ИГАСА, 2000. С.213-215.
4. Gvero T., Kuncak V. (2015). Interactive Synthesis Using Free-Form Queries // 37th IEEE International Conference on Software Engineering (ICSE). 689-692 pp. DOI: 10.1109/ICSE.2015.224.
5. Mandal S., Naskar S. Natural Language Programing with Automatic Code Generation towards Solving Addition-Subtraction Word Problems // Proceedings of 14th International Conference on Natural Language Processing (December, 2017). Jadavpur University, 2017. 146-154 pp.
6. Clark S., Curran J.R. 2007. Widecoverage efficient statistical parsing with CCG and log-linear models // Computational Linguistics 33(4). pp. 493–552.
7. Пекунов В.В. Объектно-событийные модели порождения программ // Вестник ИГЭУ.-Иваново, 2004.-Вып.3.-С.49-52.
8. Пекунов В.В. Автоматическое распараллеливание C-программ в Cilk++ стиле. Применение индукции объектно-событийных моделей.-LAP LAMBERT Academic Publishing, 2018.-105 с.
9. Perlre. URL: https://perldoc.perl.org/perlre.html
10. Link Grammar Parser. URL: https://www.abisource.com/projects/link-grammar/
11. Пекунов В.В. Параллельное решение задачи автоматического достраивания порождающей модели программы на базе конструирующих XPath-запросов // Сб. докл. межд. науч.-техн. конф. "IT-Технологии: развитие и приложения" (Владикавказ, декабрь 2019).-Владикавказ: СКГМИ (ГТУ), Изд-во "Терек", 2019.-С.105-111.
References
1. Yin P., Neubig G. A syntactic neural model for general-purpose code generation. In: ACL (1), pp. 440–450 (2017).
2. Oda Y., Fudaba H., Neubig G. et al. Learning to Generate Pseudo-code from Source Code using Statistical Machine Translation // 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2015. pp. 574-584.
3. Zubkov V. P., Nazaretskii S. P. IPGS — intellektual'naya sistema av-tomatizirovannogo programmirovaniya// Inf. sreda vuza: Sb. st. Ivanovo: IGASA, 2000. S.213-215.
4. Gvero T., Kuncak V. (2015). Interactive Synthesis Using Free-Form Queries // 37th IEEE International Conference on Software Engineering (ICSE). 689-692 pp. DOI: 10.1109/ICSE.2015.224.
5. Mandal S., Naskar S. Natural Language Programing with Automatic Code Generation towards Solving Addition-Subtraction Word Problems // Proceedings of 14th International Conference on Natural Language Processing (December, 2017). Jadavpur University, 2017. 146-154 pp.
6. Clark S., Curran J.R. 2007. Widecoverage efficient statistical parsing with CCG and log-linear models // Computational Linguistics 33(4). pp. 493–552.
7. Pekunov V.V. Ob''ektno-sobytiinye modeli porozhdeniya programm // Vestnik IGEU.-Ivanovo, 2004.-Vyp.3.-S.49-52.
8. Pekunov V.V. Avtomaticheskoe rasparallelivanie C-programm v Cilk++ stile. Primenenie induktsii ob''ektno-sobytiinykh modelei.-LAP LAMBERT Academic Publishing, 2018.-105 s.
9. Perlre. URL: https://perldoc.perl.org/perlre.html
10. Link Grammar Parser. URL: https://www.abisource.com/projects/link-grammar/
11. Pekunov V.V. Parallel'noe reshenie zadachi avtomaticheskogo dostraivaniya porozhdayushchei modeli programmy na baze konstruiruyushchikh XPath-zaprosov // Sb. dokl. mezhd. nauch.-tekhn. konf. "IT-Tekhnologii: razvitie i prilozheniya" (Vladikavkaz, dekabr' 2019).-Vladikavkaz: SKGMI (GTU), Izd-vo "Terek", 2019.-S.105-111.
Результаты процедуры рецензирования статьи
В связи с политикой двойного слепого рецензирования личность рецензента не раскрывается.
Со списком рецензентов издательства можно ознакомиться здесь.
В работе представляется опыт создания смысловых XML-моделей текстов на естественном языке из текстовых постановок задач. При этом остается нераскрытым вопрос о методах предобработки таких текстовых постановок задач, какие образом производится лексико-синтаксический разбор, какого типа элементы предложений извлекаются. Также отсуствует описание ограничений на текстовые постановки задач, можно, например, использовать сложные математические формулы или формулировки, подразумевающие вычислительные действия, но не описанные в задаче в виде последовательности действий (в примере было упоминание о рассчете среднего значения). В названии статьи используется формулировка "смысловые XML-модели текстов на естественном языке", однако в тексте статьи представлен фрагмент полученной XML-модели только в визуальной форме, что не позволяет оценить полученную XML-модель.
Значительная часть статьи посвящена описанию применение XPath-подобного языка для построения смысловой модели, приведено достачно большое количество примеров (однако часть из примеров кода программ требует более подробного описания используемых обозначений), подробно описаны новые функции и правила.
В настоящее время исследования связанные с развитием искусственного интеллекта находятся на пике популярности, и действительно одной из важных задач является генерация осмысленных текстов, в том числе текстов программ для ЭВМ, так что актуальность поставленной задачи не вызывает сомнений.
Научная новизна работы заключается в разработке методики построения смысловых XML-моделей текстов на естественном языке, включающей два этапа, на каждом из которых предлагаются оригинальные решения. Представлена апробация предложенного решения.
Статья логически последовательна, выводы и заключение обоснованы. В статье выделены только несколько достаточно объемных разделов, выделение подразделов и расстановка акцентов на используемые методы и новые результаты сделало бы статью более удобной для прочтения. Некоторые фрагменты статьи возможно следовало бы расписать более подробно или проиллюстрировть примерами, например, как выглядит первичная и финальная смысловые модели. В целом в статье применяется научный стиль изложения.
Библиографический список состоит из 11 источников, часть из которых были изданы более 10 лет назад.
Таким образом, в качестве замечаний можно отметить отсуствие описания некоторых важных составляющих в методике создания смысловых XML-моделей текстов на естественном языке (указаны в рецензии выше), достаточно сложную структуру статьи. В целом, при условии небольшой доработки, статья может быть рекомендована к публикации.
|











