|
Программные системы и вычислительные методы
Правильная ссылка на статью:
Пекунов В.В.
Автоматическое распараллеливание C-программ с применением директив Cilk++ на базе распознающих объектно-событийных моделей
// Программные системы и вычислительные методы.
2018. № 4.
С. 124-133.
DOI: 10.7256/2454-0714.2018.4.28086 URL: https://nbpublish.com/library_read_article.php?id=28086
Автоматическое распараллеливание C-программ с применением директив Cilk++ на базе распознающих объектно-событийных моделей
Пекунов Владимир Викторович
доктор технических наук
Инженер-программист, ОАО "Информатика"
153000, Россия, Ивановская область, г. Иваново, ул. Ташкентская, 90
Pekunov Vladimir Viktorovich
Doctor of Technical Science
Software Engineer, JSC "Informatika"
153000, Russia, Ivanovskaya oblast', g. Ivanovo, ul. Tashkentskaya, 90

|
pekunov@mail.ru
|
|
 |
Другие публикации этого автора
|
|
|
DOI: 10.7256/2454-0714.2018.4.28086
Дата направления статьи в редакцию:
21-11-2018
Дата публикации:
10-01-2019
Аннотация:
В данной работе рассматривается проблема автоматического распараллеливания C-программ (преимущественно вычислительного характера) с применением директив Cilk++, с помощью ограниченного набора которых может быть явно выражен параллелизм по задачам. Для решения данной проблемы формулируется концепция распознающих объектно-событийных моделей, потенциально способных к разбору и трансформации произвольных текстов. Данная концепция является развитием предложенной автором ранее теории объектно-событийных моделей, которые, в предельной постановке, эквивалентны расширенным машинам Тьюринга. Используется общий подход теории объектно-событийных моделей, утверждающей возможность описания произвольных алгоритмов с помощью указанных моделей. Предлагается технология анализа и трансформации как структурированных, так и неструктурированных текстов с применением распознающих объектно-событийных моделей. Предложена стратегия автоматического распараллеливания C-программ с применением директив Cilk++, основывающаяся на указанной технологии. На примере автоматического распараллеливания простой вычислительной программы получены данные об ускорении и эффективности распараллеливания. Утверждается, что разработанная технология может использоваться в составе системы порождения программ для распараллеливания сгенерированных программ.
Ключевые слова:
автоматическое распараллеливание, язык C, расширение Cilk, объектно-событийные модели, распознавание алгоритма, трансформация алгоритма, система порождения программ, логическое программирование, параллелизм задач, параллельные вычисления
Abstract: In this paper, the author considers the problem of automatic parallelization of C programs (mainly computational) with the use of Cilk ++ directives, with the help of a limited set of which parallelism in tasks can be clearly expressed. To solve this problem, the concept of recognizing object-event models, potentially capable of parsing and transforming arbitrary texts, is formulated. This concept is a development of the theory of object-event models proposed by the author earlier, which, in the marginal formulation, are equivalent to advanced Turing machines. A general approach of the theory of object-event models is used, which asserts the possibility of describing arbitrary algorithms using these models. The technology of analysis and transformation of both structured and non-structured texts with the use of recognizing object-event models is proposed. A strategy is proposed for automatic parallelization of C programs using Cilk ++ directives based on this technology. Using the example of automatic parallelization of a simple computing program, data on acceleration and efficiency of parallelization are obtained. It is argued that the developed technology can be used as part of a program generating system for parallelizing the generated programs.
Keywords: automatic parallelizing, C programming language, Cilk, object-event models, algorithm recognition, algorithm transformation, program generation system, logical programming, task parallelism, parallel computations
Введение
С учетом роста интенсивности применения вычислительной техники со все большим уклоном в сторону трудоемкой обработки «больших данных», существенное значение имеет применение параллельных вычислений. Это актуально не только для суперкомпьютеров, но и для персональных вычислительных машин с многоядерным процессором и, возможно, многоядерными видеокартами. При этом актуален поиск новых средств и способов автоматического распараллеливания программ [1], поскольку не все исследователи и даже не все разработчики программного обеспечения являются специалистами в такой достаточно специфической области как параллельное программирование.
По уровню анализа/переработки исходного кода программы можно выделить три уровня средств автоматического распараллеливания:
1. Распараллеливание непосредственно компилятором (при этом исходный код, с формальной точки зрения, практически не меняется), который, в частности, может применить векторные инструкции. К таким компиляторам относится, например, GNU C/C++ Compiler и, несколько условно, плагин-компилятор VAST (информация получена с сайта http://www.crescentbaysoftware.com), который работает с промежуточными представлениями компилируемой программы и может встраиваться в иные компиляторы. Это «непрозрачный» для программиста подход, кроме того сомнения вызывает эффективность выявления и реализации скрытого параллелизма по задачам, который, обычно, требует трудоемкого спекулятивного исполнения кода.
2. В более сложных случаях выполняется частичная переработка кода исходной программы специализированной системой, в который вставляются те или иные директивы распараллеливания, соответствующие одному из стандартных интерфейсов распараллеливания. Это более универсальный и потенциально более эффективный подход. В качестве примеров можно назвать системы распараллеливания YUCCA, PLUTO [2] и AutoPar [3], использующие для распараллеливания директивы OpenMP [1], S2P [4], использующую OpenMP и pThreads, а также PIPS [5], в которой используются MPI [1] и OpenMP. Здесь важное значение имеет потенциальный уровень переработки кода, которая может стать достаточно интеллектуальной задачей, эффективно решаемой, например, с помощью логического программирования. Однако нам не удалось обнаружить сведений о возможностях такого рода в вышеупомянутых системах.
3. В наиболее сложном случае возможна глубокая проработка исходного кода параллелизатором с достаточно активным диалогом с программистом, что, вероятно, позволяет в наибольшей степени выявить потенциально параллельные фрагменты и дать наиболее эффективный выходной код. Однако это, фактически, уже полуавтоматическое распараллеливание. Здесь можно назвать, например, системы ParaWise [6], Tournavitis [2] и САПФОР/ПАРФОР [7, 8].
В данной работе нас в наибольшей степени интересует универсальность подхода при условии полной автоматизации распараллеливания для C-программ, потенциально требующей решения интеллектуальных задач логического программирования, в том числе - обнаружения параллелизма по задачам. Как очевидно из вышеприведенного краткого обзора, такая задача в полной мере не решена, соответственно, данная тема является актуальной. В качестве базового выберем второй подход – частичную переработку исходного кода программы (с сохранением, в целом, его структуры) со вставкой соответствующих директив распараллеливания. При этом будем стремиться избегать вставки дополнительных разметочных директив в код (в отличие, например, от подхода, изложенного в работе [3]). В качестве средств распараллеливания выберем подмножество Cilk++, реализующее параллелизм по задачам с помощью всего двух новых ключевых слов.
Интересным вариантом платформы для реализации автоматического распараллеливания представляется система порождения программ PGEN++ [9, 10], основанная на технологии применения объектно-событийных моделей (ОСМ) и имеющая интерфейс с интерпретатором логического языка GNU Prolog. Данная технология достаточно хорошо проработана для задач прямого и/или опосредованного дедукцией порождения программ. Однако возможности ОСМ шире. В частности, доказано, что в предельном случае ОСМ может быть сведена к расширенной машине Тьюринга, способной выполнить произвольный вычислимый по Тьюрингу алгоритм. В связи с этим, достаточно интересным представляется применение ОСМ для задач, обратных или дополнительных по отношению к порождению программ, связанных с реконструкцией алгоритма по программе (то есть с распознаванием исходной концепции программы – задачей, пересекающейся с проблемой декомпиляции [11]) и его оптимизирующими (например, распараллеливающими) трансформациями. При этом, для реконструкции, можно использовать распознавание схем алгоритмов, что является одним из основных подходов в задачах такого класса (см., например, обзор, проведенный в работе [12]). Распознавание может базироваться на шаблонных заготовках типовых фрагментов программ, что хорошо вписывается в общую идеологию ОСМ. При этом, в отличие от иных работ [12], можно легко применить модифицированные регулярные выражения в сочетании с логическим программированием.
Целью данной работы является выработка новых, достаточно простых подходов к автоматизации распараллеливания C-программ на базе распознающих ОСМ с элементами логического программирования. Для достижения данной цели поставим следующие задачи: а) сформулировать кратко концепцию распознающих ОСМ и обозначить ее применение для разбора, анализа и логической трансформации входной программы, б) сформулировать базовую стратегию распараллеливания разобранной программы с выявлением параллелизма задач и его реализации средствами Cilk++. Отметим, что задача автоматического распараллеливания C-программ в такой постановке чаще решалась лишь частично (см., например, [13]), поскольку требовала особого стиля записи исходных программ. Разрабатываемая в настоящей работе технология не предполагает какого-либо особого стиля написания программ и не требует диалога с программистом.
Понятие распознающей ОСМ
Как и обычная порождающая ОСМ [9], распознающая ОСМ представляет собой сеть. Однако, в отличие от порождающей ОСМ, ее вершинами являются не экземпляры (объекты) классов (представляющих собой понятийную иерархическую модель предметной области), а сами классы, каждому из которых сопоставлен распознающий метод, предназначенный для выделения из текста информации об объектах такого класса. Каждому из распознающих методов соответствует распознающий шаблон (группа модифицированных регулярно-логических выражений) и логический скрипт (на языке GNU Prolog), позволяющий выполнять сложные интеллектуальные процедуры обработки выделенной из текста информации.
Интерпретация сети классов распознающей ОСМ, в случае распознавания структурированного текста (программы), выполняется многократно, при наступлении каждого из спланированных событий распознавания. Обычно очередное такое событие планируется, если при последовательном просмотре существует еще не обработанный фрагмент входного текста. При наступлении события сетевая структура связей между классами в модели определяет порядок применения распознающих методов классов (по идеологии «сетевого графика работ»). Первым вызывается метод, соответствующий истоку. Вызов методов (при обработке текущего события) прекращается или при достижении стока сети, или, если очередной метод успешно распознал текущий фрагмент текста. При вызове распознающего метода класса происходят следующие действия:
а) определение схожести входного фрагмента с шаблоном, связанным с распознающим методом данного класса, и, при успехе, извлечение информации из этого фрагмента;
б) генерация объекта (наполняемого распознанной информацией) данного класса, который войдет в первичную линейную порождающую ОСМ;
в) возможные трансформации (например, направленные на распараллеливание входной программы) первичной ОСМ, реализуемые логическим скриптом, связанным с соответствующим распознающим методом.
По окончании интерпретации модели имеем некоторую выходную линейную ОСМ. Если была выбрана система классов, каждый из которых описывает определенный тип оператора (цикл, ветвление, комментарий и т.п.), то такая ОСМ (в данном случае – цепочка сгенерированных объектов) в точности описывает структуру выходной программы и может породить ее текст.
Отметим еще один случай: в режиме сканирующего распознавания неструктурированного или слабо структурированного текста, сеть может интерпретироваться однократно (имеет место лишь одно событие), при этом каждый распознающий метод каждого класса за одно срабатывание находит (в соответствии с заданным поисково-переборным шаблоном) все требуемые образцы текста и генерирует по объекту для каждого из них, после чего применяется трансформирующий логический скрипт.
Автоматическое распараллеливание
Модель исходной программы (цепочечная ОСМ), полученная в результате интерпретации распознающей ОСМ, подлежит анализу и распараллеливающей трансформации. Эти действия целесообразно организовать в распознающем методе класса, соответствующего стоку распознающей ОСМ, обрабатывающему завершающее событие распознавания. При этом в его распоряжении будет полная информация о построенной модели, которую можно использовать для статического и динамического анализа исходной программы, в ходе которых в нее вставляются директивы распараллеливания. Это нетривиальная, но достаточно характерная задача для круга проблем, успешно решаемых на языке Prolog.
Автоматическое распараллеливание исходной программы заключается в следующем: а) в обнаружении функций C-программы, которые имеют существенную трудоемкость (превышающую трудоемкость порождения параллельной ветви) и могут иметь «ленивые параметры», б) в поиске и маркировке таких вызовов этих функций, которые дадут ускорение от их параллельного запуска с применением «ленивых параметров», в) в адекватной расстановке барьеров синхронизации.
Проводится статический анализ входного кода программы с целью определения, для каждой из внутренних функций, какие значения по переданным в них указателям модифицируются (истинные «ленивые» переменные, то есть такие, которые могут получить значения в процессе работы функции), а какие, фактически, являются неизменными. Также определяется набор глобальных переменных, модифицируемых каждой функцией. На основании этой информации для каждой функции составляется список ее параметров и глобальных переменных, которые она делает «ленивыми».
Собственно распараллеливание начинается с первичной (пробной) расстановки директив cilk_spawn перед каждым вызовом внутренней функции (то есть определенной в файле программы или в подключаемых ею заголовочных файлах). Далее, применяется динамический анализ: проверяются операторы, выполняемые после каждого такого вызова, и определяется оператор, в котором используются значения одной или нескольких выходных «ленивых» переменных. Перед такими операторами вставляется директива cilk_sync.
Далее проводится приблизительный расчет времени вызова (исчисляемого в некоторых условных единицах) каждой внутренней функции. Делается попытка определить, какие из запусков «в параллель» дают выигрыш по времени. С запусков, которые такой выигрыш, предположительно, не дают, директива cilk_spawn снимается. В заключение из каждой функции, в которой не осталось директив cilk_spawn, удаляются все директивы cilk_sync.
Дадим теперь более формальное описание алгоритма распараллеливающей трансформации:
1. Задаем или определяем:
Tf – среднее время исполнения функции по умолчанию (библиотечной функции с априорно неизвестным средним временем работы или функции программы, для которой расчет времени еще не производился);
Tspawn – предположительное время, затрачиваемое мастер-процессом на ответвление cilk_spawn-процесса;
Toper – предположительное среднее время выполнения одного элементарного оператора (математического выражения без вызовов функций);
Tsync – предположительное чистое время, затраченное на вызов cilk_sync (в случае, если ожидаемых процессов нет).
Эти параметры задаются в неких условных единицах (поскольку важны не конкретные значения, а их соотношение), которые можно определить с помощью предварительных тестов, проводимых на рабочей вычислительной машине с установленным необходимым программным обеспечением.
2. На входе имеем цепочку разобранных синтаксических конструкций, каждая из которых представляет собой либо законченный оператор, либо фрагмент сложной конструкции.
3. Находим вызовы внутренних функций, каждый из которых маркируем директивой cilk_spawn. Приписываем каждой функции некоторое предполагаемое время исполнения (которое далее будет итерационно уточняться) – первоначально Tf.
4. Определяем зависимости по данным для каждого оператора. Для этого находятся все идентификаторы, представляющие входные значения, используемые в операторе. Дополнительно находятся идентификаторы выходных переменных/параметров (эта информация используется, например, для определения истинных «ленивых» параметров в функциях), получающих значения в данном операторе в результате присваиваний и/или модификаций по типу инкремента/декремента.
5. Запускаем итерационный процесс уточнения параллельной разметки, который выполняется либо до прекращения изменения разметки, либо пока не будет превышено допустимое число итераций N (что полезно при наличии, например, сложной рекурсии). Потенциальная необходимость в более чем одной итерации объясняется тем, что в результате изменений разметки, соответственно, меняется и предполагаемое время исполнения внутренних функций, что каскадно влияет на величину времени исполнения зависимых от них функций. На каждой итерации выполняется динамический анализ кода каждой функции, при котором переборно анализируются все возможные направления исполнения ее кода (все альтернативы switch, все ветви if, а также условное эмулятивное «исполнение» всех циклов длиной в две итерации с учетом возможных break/continue). В ходе анализа выполняются следующие действия:
а) определяются точки использования значений «ленивых переменных» (получающих значения в теле функций, запущенных ранее по пути исполнения с директивой cilk_spawn), перед которыми вставляется директива ожидания завершения порожденных параллельных ветвей cilk_sync;
б) подсчитывается уточненное время tpi исполнения (определяется в неких условных единицах путем прямого и/или вероятностного расчета количества Ni исполняемых элементарных операторов, tpi = Ni×Toper) i-й порожденной ветви (всего n ветвей) параллельно с некоторыми сериями прочих операторов (с суммарными длительностями tni,j), следующих по некоторым j-м путям в основной ветви (начинающимся точкой ветвления и заканчивающимся выходом из текущей функции или ближайшей директивой cilk_sync);
в) определяются предположительно неэффективные по времени вызовы функций, с которых при этом снимаются cilk_spawn-пометки. Для каждой i-й директивы вычисляется среднее время досчета
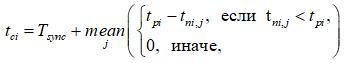
после чего условие неэффективности приобретает вид:
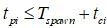 ; ;
г) из функций, не содержащих более директив параллельного ветвления cilk_spawn, удаляются все директивы cilk_sync.
В результате итерационного процесса получаем распараллеленную программу, в которой, возможно остается некоторое количество ненужных синхронизаций cilk_sync, что не оказывает существенного влияния на скорость работы полученной программы.
Результаты
Рассмотренная стратегия автоматического распараллеливания была реализована в специальном наборе порождающе-распознающих классов ОСМ в составе системы порождения и реконструкции программ PGEN++. Технология была апробирована на программе численного решения уравнения Пуассона со сложной правой частью. Автоматически распараллеленная программа была запущена на стандартной 16-ядерной (HyperThreading-ядра) вычислительной системе (в рамках проекта Penguin-On-Demand фирмы Penguin Computing), результаты замеров времени работы сведены в таблицу 1 – очевиден положительный эффект, подтверждающий адекватность проведенного автоматического распараллеливания. С увеличением числа ядер от 1 до 8 имеем рост ускорения. Насыщение наступает при использовании 8 ядер, что соответствует физическому числу ядер примененной вычислительной системы. Дальнейшее увеличение числа ядер дает лишь падение ускорения, что объясняется сочетанием двух факторов:
а) с увеличением числа ядер уменьшается объем полезной работы, приходящейся на ядро, при этом величина временных затрат на организацию параллельной работы растет. В результате, временные затраты на распараллеливание могут сравняться со временем полезной работы на ядре и даже превысить его, что приводит лишь к увеличению общего времени работы;
б) технология HyperThreading не всегда дает увеличение производительности, например, если два потока на HyperThreading-ядре постоянно конкурируют за внутренние общие ресурсы этого ядра. Поэтому, в нашем случае, при использовании более 8 ядер, когда включается режим HyperThreading, достаточно трудно ожидать ощутимого увеличения производительности.
Проиллюстрируем экспериментально полученную зависимость ускорения от числа ядер аналитически. Пусть t(N) – время, затраченное на исполнение программы при использовании N ядер. Если q - доля вычислений, которые не поддаются распараллеливанию, то в идеальном случае могло бы иметь место соотношение:
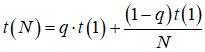 . .
Однако в реальном случае необходимо также учесть дополнительные временные затраты ta(N) на организацию параллельной работы, которые, обычно, считаются линейно зависимыми от числа ядер N:
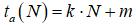 , ,
где k, m - эмпирические коэффициенты. Поэтому
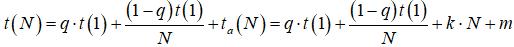 . .
Если произвести элементарный анализ функции t(N) на наличие экстремумов (с помощью нахождения производной), то, с учетом того, что t(1) > 0, k > 0, N > 0, 1 > q > 0, легко определить, что единственный имеющий смысл экстремум - минимум, достигаемый при
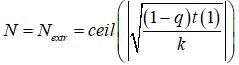 . .
Такое поведение t(N) хорошо согласуется с данными, приведенными в таблице 1. Из таблицы очевидно, что в нашем случае Nextr = 8.
Ускорение S(N) и эффективность распараллеливания E(N) в зависимости от числа задействованных ядер N рассчитывались по общепринятым соотношениям [1]:
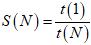 ; ;
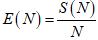 . .
Поскольку t(1) = const, t(1) > 0, легко видеть, что функция ускорения S(N) имеет единственный максимум, в той же точке, что и минимум t(N):
N = Nextr.
Такое поведение S(N) полностью согласуется с данными, приведенными в таблице 1. Максимум наблюдается при
N = Nextr = 8.
Что же касается эффективности распараллеливания, то она стабильно уменьшается с увеличением числа ядер: в приемлемой степени при использовании от 1 до 8 ядер, и, более резко, при использовании более 8 ядер. Такой эффект вполне закономерен, согласуется с приведенными данными об ускорении и также объясняется, во-первых, последовательным увеличением непроизводительных временных затрат на организацию параллельной работы с ростом числа ядер N и, во-вторых, существенной конкуренцией за ресурсы HyperThreading-ядер при использовании более 8 ядер.
Таблица 1. Результаты замеров характеристик исполнения распараллеленной программы
|
Число ядер N
|
1
|
2
|
3
|
4
|
6
|
8
|
10
|
12
|
14
|
|
Время счета, с
|
17,89
|
10,28
|
7,19
|
5,84
|
4,54
|
4,17
|
4,42
|
5,54
|
6,54
|
|
Ускорение S(N)
|
-
|
1,74
|
2,49
|
3,06
|
3,94
|
4,29
|
4,05
|
3,23
|
2,74
|
|
Эффективность E(N)
|
-
|
0,87
|
0,83
|
0,77
|
0,66
|
0,54
|
0,41
|
0,27
|
0,2
|
Выводы
Итак, в данной работе предложен новый вид ОСМ (распознающие ОСМ) и сформулирован подход к их применению для распознавания, анализа и логической трансформации структурированных текстов (программ). Описана стратегия автоматического распараллеливания C-программ с применением Cilk++ разметки, реализованная на базе распознающих ОСМ в системе PGEN++.
Стратегия отличается следующими положительными особенностями:
а) не требует диалогового режима и особого стиля записи исходных программ;
б) в полной мере основана на логическом программировании, что, технически, позволяет выполнять интеллектуальные распараллеливающие алгоритмы;
в) использует приближенные расчеты условного времени исполнения функций, что позволяет повысить эффективность распараллеливания за счет отсеивания случаев, в которых распараллеливание предположительно невыгодно.
На примере простой вычислительной программы продемонстрировано, что автоматическое распараллеливание с применением разработанной стратегии дает существенное ускорение ее работы на многоядерной системе, запущенной в рамках проекта Penguin-On-Demand. Более того, предложенная стратегия способна реализовать автоматическое порождение параллельных C-программ в системе PGEN++ (на первом этапе система порождает по описанию задачи код непараллельной программы, на втором этапе программа автоматически распараллеливается).
Библиография
1. Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. СПб.: БХВ-Петербург, 2002. 608 с.
2. Castro-Godínez, Jorge Alberto. Sequential code parallelization for multi-core embedded systems: A survey of models, algorithms and tools [Электронный ресурс] // Proyecto de Graduación (Maestría en Ingeniería en Electrónica) Instituto Tecnológico de Costa Rica, Escuela de Electrónica, 2014. URL: http://hdl.handle.net/2238/7128 (дата обращения: 20.11.2018).
3. Liao C., Quinlan D.J., Willcock J.J. et al. Semantic-Aware Automatic Parallelization of Modern Applications Using High-Level Abstractions // Int J Parallel Prog. 2010. Vol.38. P.361-378.
4. Randive V., Vaidya V. G. Parallelization tools [Электронный ресурс]. URL: https://www.kpit.com/resources/downloads/research-papers/parallelization-tools.pdf (дата обращения: 19.11.2018).
5. Ancourt C., Coelho F., Creusillet B. and Keryell R. How to Add a New Phase in PIPS: the Case of Dead Code Elimination // Sixth Workshop «Compilers for Parallel Computers» (CPC 96). Aachen, 1996. P.19-30.
6. Система ParaWise [Электронный ресурс]. URL: www.parallelsp.com (дата обращения: 20.11.2018).
7. Бахтин В.А., Клинов М.С., Крюков В.А., Поддерюгина Н.В. Автоматическое распараллеливание последовательных программ для многоядерных кластеров. //Труды Международной научной конференции "Научный сервис в сети Интернет: суперкомпьютерные центры и задачи". М.: Изд-во МГУ, 2010. С.12-15.
8. Клинов М.С., Крюков В.А. Автоматическое распараллеливание Фортран-программ. Отображение на кластер. // Труды международной научной конференции научной конференции "Параллельные вычислительные технологии" (ПаВТ'2009). Челябинск: Изд-во ЮУрГУ, 2009. С.227-237.
9. Пекунов В.В. Автоматизация параллельного программирования при моделировании многофазных сред. Оптимальное распараллеливание // Автоматика и телемеханика. 2008. №7. С.170-180.
10. Пекунов В.В. Новые методы параллельного моделирования распространения загрязнений в окрестности промышленных и муниципальных объектов // Дис. докт. тех. наук. Иваново, 2009. 274 с.
11. Трошина Е.Н., Чернов А.В. Инструментальная среда восстановления исходного кода программы-декомпилятор TyDec // Прикладная информатика. 2010. № 4 (28). С.73-97.
12. Taherkhani A. Automatic Algorithm Recognition Based on Programming Schemas and Beacons: A Supervised Machine Learning Classification Approach [Электронный ресурс] // Doctoral Dissertation. Aalto University, 2013. 254 pp. URL: http://lib.tkk.fi/Diss/2013/isbn9789526049908/isbn9789526049908.pdf (дата обращения: 19.11.2018).
13. Шаповалов О.В., Андреев А.Е., Фоменков С.А. Разработка методов автоматизации распараллеливания программ для систем с общей памятью // Известия ЮФУ. Технические науки. 2015. №3 (164). С.24-35.
References
1. Voevodin V.V., Voevodin Vl.V. Parallel'nye vychisleniya. SPb.: BKhV-Peterburg, 2002. 608 s.
2. Castro-Godínez, Jorge Alberto. Sequential code parallelization for multi-core embedded systems: A survey of models, algorithms and tools [Elektronnyi resurs] // Proyecto de Graduación (Maestría en Ingeniería en Electrónica) Instituto Tecnológico de Costa Rica, Escuela de Electrónica, 2014. URL: http://hdl.handle.net/2238/7128 (data obrashcheniya: 20.11.2018).
3. Liao C., Quinlan D.J., Willcock J.J. et al. Semantic-Aware Automatic Parallelization of Modern Applications Using High-Level Abstractions // Int J Parallel Prog. 2010. Vol.38. P.361-378.
4. Randive V., Vaidya V. G. Parallelization tools [Elektronnyi resurs]. URL: https://www.kpit.com/resources/downloads/research-papers/parallelization-tools.pdf (data obrashcheniya: 19.11.2018).
5. Ancourt C., Coelho F., Creusillet B. and Keryell R. How to Add a New Phase in PIPS: the Case of Dead Code Elimination // Sixth Workshop «Compilers for Parallel Computers» (CPC 96). Aachen, 1996. P.19-30.
6. Sistema ParaWise [Elektronnyi resurs]. URL: www.parallelsp.com (data obrashcheniya: 20.11.2018).
7. Bakhtin V.A., Klinov M.S., Kryukov V.A., Podderyugina N.V. Avtomaticheskoe rasparallelivanie posledovatel'nykh programm dlya mnogoyadernykh klasterov. //Trudy Mezhdunarodnoi nauchnoi konferentsii "Nauchnyi servis v seti Internet: superkomp'yuternye tsentry i zadachi". M.: Izd-vo MGU, 2010. S.12-15.
8. Klinov M.S., Kryukov V.A. Avtomaticheskoe rasparallelivanie Fortran-programm. Otobrazhenie na klaster. // Trudy mezhdunarodnoi nauchnoi konferentsii nauchnoi konferentsii "Parallel'nye vychislitel'nye tekhnologii" (PaVT'2009). Chelyabinsk: Izd-vo YuUrGU, 2009. S.227-237.
9. Pekunov V.V. Avtomatizatsiya parallel'nogo programmirovaniya pri modelirovanii mnogofaznykh sred. Optimal'noe rasparallelivanie // Avtomatika i telemekhanika. 2008. №7. S.170-180.
10. Pekunov V.V. Novye metody parallel'nogo modelirovaniya rasprostraneniya zagryaznenii v okrestnosti promyshlennykh i munitsipal'nykh ob''ektov // Dis. dokt. tekh. nauk. Ivanovo, 2009. 274 s.
11. Troshina E.N., Chernov A.V. Instrumental'naya sreda vosstanovleniya iskhodnogo koda programmy-dekompilyator TyDec // Prikladnaya informatika. 2010. № 4 (28). S.73-97.
12. Taherkhani A. Automatic Algorithm Recognition Based on Programming Schemas and Beacons: A Supervised Machine Learning Classification Approach [Elektronnyi resurs] // Doctoral Dissertation. Aalto University, 2013. 254 pp. URL: http://lib.tkk.fi/Diss/2013/isbn9789526049908/isbn9789526049908.pdf (data obrashcheniya: 19.11.2018).
13. Shapovalov O.V., Andreev A.E., Fomenkov S.A. Razrabotka metodov avtomatizatsii rasparallelivaniya programm dlya sistem s obshchei pamyat'yu // Izvestiya YuFU. Tekhnicheskie nauki. 2015. №3 (164). S.24-35.
|















